概要
ソフトパーティクルの仕組みを応用した表現について色々とメモしておこうと思います。
(よく利用しようと思うこともあるものの、毎回調べたり、というのがめんどくさいので)
ちなみにソフトパーティクルとは、いわゆるパーティクルが通常のオブジェクトと重なる場合に、深度値を用いて重なり具合に応じてフェードを掛けることで、パーティクルの重なり部分をソフトに見せる(エッジを目立たなくさせる)目的で使われるものです。
これをパーティクル以外に利用することで、オブジェクトが他のオブジェクトに近い場合にフェードさせじんわりと重ねることができるようになります。
なお、今回も下記の凹みさんの記事を大いに参考にさせていただきました。
(いつもありがとうございます)
実際に実行すると以下のようになります。(右はワイヤーフレームを追加したもの)

コード解説
さて、まずはコード全容から。
コード量はそこまで多くありません。
Shader "Unlit/SoftParticle"
{
Properties
{
_MainTex ("Texture", 2D) = "white" {}
_InvFade("Inv fade", Range(0, 1)) = 1
}
SubShader
{
Tags { "RenderType"="Transparent" "Queue"="Transparent" }
LOD 100
Pass
{
Blend SrcAlpha OneMinusSrcAlpha
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
#include "UnityCG.cginc"
struct appdata
{
float4 vertex : POSITION;
float2 uv : TEXCOORD0;
};
struct v2f
{
float2 uv : TEXCOORD0;
float4 vertex : SV_POSITION;
float4 projPos : TEXCOORD1;
};
sampler2D _MainTex;
float4 _MainTex_ST;
float _InvFade;
// デプステクスチャの宣言
UNITY_DECLARE_DEPTH_TEXTURE(_CameraDepthTexture);
v2f vert (appdata v)
{
v2f o;
o.vertex = UnityObjectToClipPos(v.vertex);
// ワールド空間座標を元に、スクリーンスペースでの位置を求める
o.projPos = ComputeScreenPos(o.vertex);
// 求めたスクリーンスペースでの位置のz値からビュー座標系での深度値を求める
COMPUTE_EYEDEPTH(o.projPos.z);
o.uv = TRANSFORM_TEX(v.uv, _MainTex);
return o;
}
fixed4 frag (v2f i) : SV_Target
{
fixed4 col = tex2D(_MainTex, i.uv);
// 深度バッファからフェッチした値を使って、リニアな深度値に変換する
float sceneZ = LinearEyeDepth(SAMPLE_DEPTH_TEXTURE_PROJ(_CameraDepthTexture, UNITY_PROJ_COORD(i.projPos)));
float partZ = i.projPos.z;
// フェード処理
float fade = saturate(_InvFade * (sceneZ - partZ));
col.a *= fade;
return col;
}
ENDCG
}
}
}
ソフトパーティクルを実現するための処理を、順を追って見ていきましょう。
ComputeScreenPos
ComputeScreenPosの定義は以下。
inline float4 ComputeScreenPos(float4 pos) {
float4 o = ComputeNonStereoScreenPos(pos);
#if defined(UNITY_SINGLE_PASS_STEREO)
o.xy = TransformStereoScreenSpaceTex(o.xy, pos.w);
#endif
return o;
}
// -------------------
inline float4 ComputeNonStereoScreenPos(float4 pos) {
float4 o = pos * 0.5f;
o.xy = float2(o.x, o.y*_ProjectionParams.x) + o.w;
o.zw = pos.zw;
return o;
}
シングルパスステレオレンダリングかどうかで分岐が入っていますが、今回はソフトパーティクルの説明なのでこちらは割愛します。(基本概念が分かればVR対応も容易いと思うので)
ComputeNonStereoScreenPosの引数に渡ってくるposは、UnityObjectToClipPosでクリップ座標空間に変換された位置、すなわち-w ~ wの範囲(グラフィックスAPIによっては0 ~ w)に変換された値が渡ってきます。
冒頭の計算が行っていることを、細かいことを省いてやっていることだけに着目すると、
float4 o = pos * 0.5f; o.xy = o.xy + o.w;
ということです。
ここで行っているのは-w ~ wを半分にして(-0.5w ~ 0.5w)、0.5wを足す、つまり0 ~ wの範囲に変換している、ということです。
ちなみに_ProjectionParams.xをyに掛けているのはプラットフォームごとの違いを吸収する目的で行っているのみで、計算の本質に違いはありません。
そして最後に、半分にしてしまったzwの値をもとに戻す目的でo.zw = pos.zw;を再代入しています。
余談
wの意味。
3Dグラフィクスでは3D空間を正規化デバイス座標系という座標系に変換し、そののちにビューポート(つまりディスプレイ)座標に変換して画面に映像を出力します。
この正規化デバイス座標系では頂点xyzの値が-1 ~ 1に変換されます。 (グラフィクスAPIによっては0 ~ 1になる)
そのために正規化と呼ばれるわけですね。
そしてこの-1 ~ 1に変換するために使われる値がwなのです。
具体的にはwで除算することで-1 ~ 1に変換します。
本来ならこのwで除算の部分はGPU側が自動で行ってくれるため、シェーダ内では-w ~ wの間になる状態までの計算に留めておいています。
ただ今回の例では、さらにそこからシェーダ内で深度値を利用するため自分でwで除算して値を求めているというわけです。
このあたりの詳しい説明はマルペケさんのこちらの記事(その70 完全ホワイトボックスなパースペクティブ射影変換行列)に詳しく書かれているのでご覧ください。
またパースペクティブ行列関連については以前、Qiitaにまとめているので詳しくはそちらをご覧ください。
COMPUTE_EYEDEPTH
次にCOMPUTE_EYEDEPTHの定義を見てみましょう。
#define COMPUTE_EYEDEPTH(o) o = -UnityObjectToViewPos( v.vertex ).z
inline float3 UnityObjectToViewPos( in float3 pos )
{
return mul(UNITY_MATRIX_V, mul(unity_ObjectToWorld, float4(pos, 1.0))).xyz;
}
COMPUTE_EYEDEPTHはマクロとして定義されており、定義からは引数に指定された変数へ計算結果を格納する形になっています。
そして計算自体はUnityObjectToViewPosによって行われ、その結果のz値が代入されています。
UnityObjectToViewPos
続けてUnityObjectToViewPosを見てみましょう。
こちらはインライン関数になっていて引数にfloat3を受け取ります。
注意してほしいのは、COMPUTE_EYEDEPTHのマクロではv.vertexという変数が宣言されている前提で計算が行われている点です。
これは頂点シェーダに渡ってきた頂点そのものです。
そしてこれを加工した結果のz値を使っているわけです。
計算式を改めて見てみると、
return mul(UNITY_MATRIX_V, mul(unity_ObjectToWorld, float4(pos, 1.0))).xyz;
となっています。
ワールド座標への変換とビュー座標への変換を行っています。
つまり、引数に与えられた頂点位置をビュー座標空間へ変換しているだけですね。
そしてCOMPUTE_EYEDEPTHは「そのz値を格納している」と書きました。
これはカメラから見た頂点のz値を計算しているわけです。
デプスの算出
次に見るのはデプスの算出部分です。
コードを抜粋すると以下の箇所。
float sceneZ = LinearEyeDepth(SAMPLE_DEPTH_TEXTURE_PROJ(_CameraDepthTexture, UNITY_PROJ_COORD(i.projPos)));
UNITY_PROJ_COORD
順番に見ていきましょう。
UNITY_PROJ_COORDの定義は以下です。なにもせずにそのまま値を返しています。
凹みさんの記事によるとPS Vitaのときだけ違う計算が行われるようですが、基本的にここは無視してよさそうです。
#define UNITY_PROJ_COORD(a) a
SAMPLE_DEPTH_TEXTURE_PROJ
次はSAMPLE_DEPTH_TEXTURE_PROJ。
これも定義を見てみましょう。
# define SAMPLE_DEPTH_TEXTURE_PROJ(sampler, uv) (tex2Dproj(sampler, uv).r)
内容はシンプルですね。
tex2Dprojのラッパーになっていて、さらにフェッチしたテクスチャの値のr成分だけを返しています。
元々引数に取るテクスチャはデプステクスチャなので、対象のr成分だけで大丈夫なわけですね。
ちなみにtex2Dprojについてですが、以前書いた以下の記事で少しだけ言及しています。
引用すると以下のような計算を行っています。
tex2Dprojは、該当オブジェクトにテクスチャを投影するような形でテクセルをフェッチします。 つまり、同次座標系で見た場合に、該当のテクセルがどうなるか、を計算しているわけです。
具体的には、以下のように自前で計算することでも同じ結果を得ることができます。
float2 uv = i.uvgrab.xy / i.uvgrab.w; half4 col = tex2D(_GrabTexture, uv);
要は、Z方向の膨らみを正規化することで2D平面(ディスプレイ)のどの位置に、該当オブジェクトのピクセルがくるのか、を計算しているわけですね。
イメージ的には以下の図のような感じです。

これは以前書いた以下の記事から引用したものです。
これでテクスチャからの値を取得することができました。
しかしまだこのままの値では、前段で説明した「ビュー空間でのz値」と組み合わせて計算を行うことができません。
なぜなら、テクスチャからフェッチした値はまだビュー空間での値ではないからです。
そこで利用するのが最後のLinearEyeDepthです。
LinearEyeDepth
こちらもさっそく定義を見てみましょう。
inline float LinearEyeDepth( float z )
{
return 1.0 / (_ZBufferParams.z * z + _ZBufferParams.w);
}
計算自体はシンプルですが、ぱっと見なにをしているか分かりませんね。
まず_ZBufferParamsがなにかを突き止めましょう。ドキュメントは以下です。
ドキュメントによると以下のように記述されています。
Z バッファ値をリニア化するために使用します。 x は (1-far/near)、 y は (far/near)、 z は (x/far)、 w は (y/far) です。
これを展開して整理すると以下のような計算を行っていることになります。
値の意味は分かりましたが、なぜこんな計算になるのでしょうか。
これを紐解くために、いつもお世話になっているマルペケさんの以下の記事を参考に考えてみます。
マルペケさんの記事にも書かれている通り、深度値は線形な変化をしません。むしろ極端な変化をします。
マルペケさんの記事から画像を引用させていただくと、以下のように極端なグラフになります。
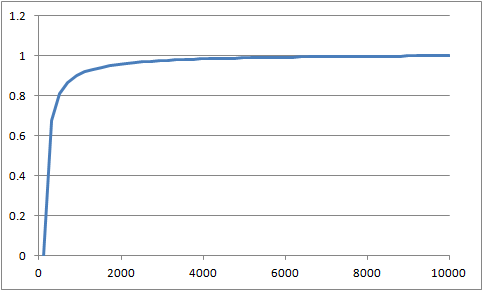
だいぶ極端なグラフです。
これを線形に戻すということは、このグラフを求める計算の逆関数を求めればいいことになります。
ただ、マルペケさんの記事で紹介されていた計算式の逆関数を求めてもLinearEyeDepthの実装のようにはならず、クロスプラットフォーム対応など他の要素の兼ね合いでこうなっていると思うので詳細までは分かりませんでした;(詳しい方いたらコメントください・・・)
とはいえ、ここで行っているのはこの極端なグラフを線形に変換するのでLinearEyeDepthという名前がついているということですね。
余談
ちなみにマルペケさんの記事で紹介されていた式は以下です。
これの逆関数は以下になりました。
デプスを用いたフェード処理
最後の部分は実際に計算を行っている部分です。
コードを抜粋すると以下の部分ですね。
float sceneZ = LinearEyeDepth(SAMPLE_DEPTH_TEXTURE_PROJ(_CameraDepthTexture, UNITY_PROJ_COORD(i.projPos))); float partZ = i.projPos.z; // フェード処理 float fade = saturate(_InvFade * (sceneZ - partZ)); col.a *= fade;
LinearEyeDepthを用いて深度バッファから得た深度値を線形に変換し、さらに今計算中のフラグメントの深度値を利用してフェードする係数として利用しています。(sceneZ - partZ)
_InvFadeはどの程度フェードさせるかをプロパティから設定するための変数です。
これを0 ~ 1の範囲にクランプし、アルファに乗算してやることで今回のフェードを実現している、というわけです。
depthTextureModeをオンに
プラットフォームの設定などによってはなにもしないとDepth Textureが取れない場合があるので、その場合は明示的にオンにしてやる必要があります。
具体的には以下のようにスクリプトから設定してやる必要があります。
(なにか適当なスクリプトから、メインカメラに対して以下を実行してやればOKです)
GetComponent().depthTextureMode |= DepthTextureMode.Depth;
最後に
色々と深度値周りの計算について見てきました。
利用するにあたっては以下の2点の違いに注意が必要です。
- 通常の計算で出た深度値
- 深度バッファから得られる値
ただ、これが分かってしまえばあとは単純な数値比較のみになるので、実際の計算自体はむずかしくないと思います。
またソフトパーティクル以外でも、深度値を取得してなにかをするというのは利用価値があると思うので覚えておくといいテクニックですね。