Unity で MQTT を使って IoT デバイスと通信する

はじめに
最近は IoT を使ってなにかできないか色々模索中です。特に、AI と絡めることでできることが一気に広がる感じがしてとても楽しいです。
下の画像は ESP32 のボードに LED を光らせる仕組みを、M5StickCPlus に MQTT ブローカーと(デバッグ用の)Web サーバを立ち上げて、ブラウザからメッセージを飛ばすと LED が光る、というデモの様子です。(本当は赤外線を飛ばす予定。ただ分かりづらいので動画では普通の LED に差し替えましたw)
最近、遅ればせながらIoTで色々模索中。AIと絡めることでできることが一気に拡大する。あとシンプルに新しいことやるのが楽しいw#AI #IoT pic.twitter.com/Tbcwel0kvz
— edom18@XR / MESON CTO (@edo_m18) 2025年9月30日
今回は色々試していく中で、Unity で MQTT を使って IoT デバイスにメッセージを飛ばす部分について書こうと思います。また、せっかくなのである程度意味があることを実現したいなと思い、Meta Quest の音量を M5Stick に飛ばして可視化する、というのをやってみました。なぜこれを作ったかというと、Quest を使った展示をしていると気づかないうちに音量が下がっていたりして、無音で体験してもらってしまう問題があったためにその対策として作りました。
▼ 今回実装したもの
以下は Meta Quest 版ではなく MQTT を叩くだけのシンプルな実装のものです。ただ、Quest でも動作するのは確認済みなので適宜コピーして利用してください。
▼ 動作している様子
UnityでMQTT通信。ブローカー、クライアントどちらも動く。#Unity #madewithunity #MQTT pic.twitter.com/08owl2klVv
— edom18@XR / MESON CTO (@edo_m18) 2025年10月4日
MQTT とは
MQTT は「Message Queuing Telemetry Transport」の略とされていますが、Queuing の機能はなく名称だけが残っているようです。HTTP よりも軽量なため消費電力が少なく、非同期な双方向通信が可能です。そのため IoT に最適なメッセージングプロトコルです。Pub/Sub パターンを採用しており、非同期に 1 対多の通信が可能です。特に大事なのは組み込みデバイスやセンサーなど、メモリやネットワーク環境に制限があるような状況を想定して作られている点です。そのため IoT を用いた開発では重要になってくる技術です。
MQTT 自体の詳細な解説はここでは割愛します。どんなものかを知りたい方は以下の記事が参考になります。
ライブラリ選定について
今回使用しているのは MQTTnet というライブラリです。これ以外にも M2Mqtt というライブラリもあるのですが、ChatGPT に聞いてみたところ MQTTnet を進められたのでこちらを利用しています。
かいつまんでオススメの理由を書くと以下のように説明されました。
- メンテ状況が圧倒的に新しい
- プロトコル対応が広い(MQTT v5 対応)
- トランスポート種別が豊富で Unity と相性が良い
環境構築
前述の通り、今回は MQTTnet を利用するためその環境を構築します。MQTTnet は NuGet で提供されているためまずは NuGet for Unity をインストールします。
インストールしたら Window メニューから NuGet > Manager NuGet Packages を選択しマネージャを開きます。

.NET のバージョンなどによって動作する・しないがありそうなので、少し前の 3.1.2 をインストールしました。
実装
今回は M5StickC-Plus というデバイスから Android / iOS アプリに接続してトピックを購読する形にしました。
▼ 動作させている様子
MQTTnet ではクライアントもブローカーもどちらも実装できるため、ブローカー役を Android、publish するクライアント役を iOS で実行してみました。
ブローカー側の実装
ブローカー側の実装の解説です。ポイントごとに解説します。コード全文は GitHub にアップしてあるのでそちらをご覧ください。
以下はブローカーを起動する部分のコード断片です。
// 1) サーバ(ブローカー)生成 MqttFactory mqttFactory = new MqttFactory(); _mqttServer = mqttFactory.CreateMqttServer();
MqttFactory クラスのインスタンスを生成し、そこから IMqttServer インターフェースを実装したサーバのインスタンスを得ます。
// 2) オプション設定 // - デフォルトエンドポイント(=TCP)を有効化し、1883で待ち受け // - 認証/認可や発行・購読のインターセプタは必要に応じて追加 MqttServerOptionsBuilder optionsBuilder = new MqttServerOptionsBuilder() .WithDefaultEndpoint() .WithDefaultEndpointPort(_port) .WithDefaultEndpointBoundIPAddress(IPAddress.Any) .WithoutEncryptedEndpoint() .WithApplicationMessageInterceptor(context => { // 発行メッセージのフィルタ // 例)特定トピックのみ許可、メッセージ書き換え 等 context.AcceptPublish = true; // 全許可(必要に応じて条件分岐) });
サーバを起動する際に利用するオプションを、ビルダーパターンで生成します。今回はサンプルのため基本的な設定のみ行っています。本番運用する場合は認証などの設定を追加したほうがいいでしょう。
// 3) イベント購読 _mqttServer.ClientConnectedHandler = new MqttServerClientConnectedHandlerDelegate(args => { Debug.Log($"[Connected] ClientId={args.ClientId}"); }); _mqttServer.ClientDisconnectedHandler = new MqttServerClientDisconnectedHandlerDelegate(args => { Debug.Log($"[Disconnected] ClientId={args.ClientId} Reason={args.DisconnectType}"); }); _mqttServer.ApplicationMessageReceivedHandler = new MqttApplicationMessageReceivedHandlerDelegate(args => { string payload = args.ApplicationMessage?.Payload == null ? null : Encoding.UTF8.GetString(args.ApplicationMessage.Payload); string display = $"[Received] Topic={args.ApplicationMessage?.Topic} " + $"QoS={(args.ApplicationMessage?.QualityOfServiceLevel)} Retain={args.ApplicationMessage?.Retain} " + $"Payload='{payload}'"; Debug.Log(display); _context.Post(_ => { _receivedText.text = display; }, null); });
各種イベントを購読します。今回は主にログ出力のために購読しています。ブローカーとしての振る舞いのみでよければこのあたりの購読は不要です。
// 4) サーバ起動 IMqttServerOptions options = optionsBuilder.Build(); await _mqttServer.StartAsync(options);
設定が完了したらサーバを起動します。起動する際に、先ほど作成したオプションを指定します。
Android で謎のエラーが出るので対処
実は実際のコードでは以下のようにエラーハンドリングをしています。
catch (Exception e) { if (e.Message.ToLower().Contains("Address already in use".ToLower())) { // NOTE: なぜか Android だと正常にサーバが起動しても "Address already in use" 例外が発生するので無視する success = true; } else { Debug.LogError($"Failed to start MQTT broker: {e.Message}"); } } finally { if (success) { string ip = GetLocalIPAddress(); string hostInfo = ip != string.Empty ? $"{ip}:{_port}" : $"localhost:{_port}"; Debug.Log($"MQTT broker started at {hostInfo}"); _context.Post(_ => { _statusText.text = $"Broker started at {hostInfo}"; }, null); } }
なぜか Android 実機でだけ、正常にサーバが起動しているにも関わらず Address already in use のエラーが発生します。しかし、実際にはサーバが起動しているため正常に動作します。
MQTTnet のリポジトリの issue にも同様の現象を報告しているものがありました。2022 年の issue なのですが、実害がないからなのか Open のままになっているようです・・。
そのため、エラー内容を見てもし Address already in use だったら無視するようにしています。ただ、本当にポートが使われているなどの理由でこのエラーが出ている場合もあるため、実際の運用をする場合は注意が必要です。
基本的にサーバ側の実装は以上です。無事に起動できたら UI に起動済みであること、IP アドレスなどが表示されるようになっています。
※ MQTT の通信のコールバックはメインスレッド外で通知されるため、nGUI に表示する場合はメインスレッドに切り替えて行う必要がある点に注意してください。
クライアント側の実装
次はクライアント側の実装です。今回のサンプルでは主にパブリッシュがメインとなっていますが、エコー用にサブスクライブもしているのでサブスクライブするパターンも網羅しています。
_mqttClient = new MqttFactory().CreateMqttClient(); _mqttClient.ApplicationMessageReceivedHandler = new MqttApplicationMessageReceivedHandlerDelegate(OnAppMessage); _mqttClient.ConnectedHandler = new MqttClientConnectedHandlerDelegate(OnConnected); _mqttClient.DisconnectedHandler = new MqttClientDisconnectedHandlerDelegate(OnDisconnected); // ---- 中略 ---- IMqttClientOptions options = CreateClientOptions(); await _mqttClient.ConnectAsync(options, CancellationToken.None);
まずはサーバへの接続部分です。サーバと同様に MqttFactory クラスを介してクライアントインスタンスを取得します。
サーバと同様に各種イベントを購読しています。またサーバと同様、接続用のオプションも生成が必要です。
オプション生成は以下のようになっています。
private IMqttClientOptions CreateClientOptions() { string host = _hostInputField.text; if (string.IsNullOrEmpty(host)) { host = "localhost"; } if (!int.TryParse(_portInputField.text, out int port)) { port = 1883; } string topic = _topicInputField.text; if (string.IsNullOrEmpty(topic)) { topic = "get/volume"; } _topic = topic; MqttClientOptionsBuilder optionsBuilder = new MqttClientOptionsBuilder() .WithTcpServer(host, port); if (_useCredentials) { optionsBuilder.WithCredentials(_username, _password); } if (_useTls) { optionsBuilder.WithTls(); } return optionsBuilder.Build(); }
サーバ接続に必要な情報を設定します。特に、インターネット上にあるサービスを利用する場合は TLS を利用することや、ユーザ名・パスワードが必要な場合があるため、それを利用するかで分岐しています。
今回はサンプルなので認証周りは不要です。メソッドの最後でビルドしたものを返しています。
接続完了はコールバックで通知されるので、そのコールバック内でサブスクライブなどを行います。
private async void OnConnected(MqttClientConnectedEventArgs args) { Debug.Log("MQTT broker connected."); _unityContext.Post(_ => { _statusText.text = "Connected"; _connectButton.GetComponentInChildren<TMP_Text>().text = "Disconnect"; _connectButton.interactable = true; _publishButton.interactable = true; }, null); if (string.IsNullOrEmpty(_topicInputField.text)) { Debug.Log("Topic is empty. Subscription skipped."); _receivedText.text = "Topic is empty. Please enter a valid topic."; return; } await _mqttClient.SubscribeAsync(new MqttTopicFilterBuilder().WithTopic(_topic).Build()); Debug.Log($"TOPIC [{_topic}] Subscribed."); }
サーバと同様、コールバックはメインスレッド外で通知されるのでメインスレッドで UI を更新するのを忘れないようにしてください。
トピックのサブスクライブは SubscribeAsync() メソッドで行います。サブスクライブ対象のトピックはビルダークラスがあるのでそれを利用して設定します。
サブスクライブしたトピックに通知がきたらコールバックでこれを受け取ります。コールバックの処理は以下です。
private void OnAppMessage(MqttApplicationMessageReceivedEventArgs args) { string payload = Encoding.UTF8.GetString(args.ApplicationMessage.Payload); Debug.Log($"Received message: Topic = {args.ApplicationMessage.Topic}, Payload = {payload}"); _unityContext.Post(_ => { _receivedText.text = payload; }, null); }
Payload は UTF-8 で受信するため、それをテキストに変換します。今回は取得した Payload をただ UI に表示するだけですが、実際にはここで内容を見て処理を行うことになります。
以下はパブリッシュ処理です。
private async void Publish() { try { Debug.Log("Publish message."); MqttApplicationMessage message = new MqttApplicationMessageBuilder() .WithTopic(_topic) .WithPayload(_payloadInputField.text) .WithAtLeastOnceQoS() .WithRetainFlag() .Build(); await _mqttClient.PublishAsync(message, CancellationToken.None); } catch (Exception e) { Debug.Log($"Failed to publish message: {e.Message}"); } }
パブリッシュするには PublishAsync() メソッドを使います。引数はこちらも他と同様にビルダーパターンで生成します。
今回はトピックとペイロード、QoSを設定して送信しています。
以上でサーバとクライアントの実装解説は終了です。MQTTnet を使うことでかなり簡単に実装できることが分かります。
次は、ここで実装したブローカーに実際に接続する IoT デバイス側の実装を紹介します。
M5StickC-Plus は Arduino IDE という IDE で開発を行います。ただ、こちらの解説を入れるとだいぶ長くなってしまうためここでは割愛します。このあたりについては別のブログ記事で解説しているので、詳細はそちらをご覧ください。ただ、M5StickC-Plus はまた少し違うセットアップが必要なので、適宜別の記事も参照ください。
M5StickC-Plus 側の実装
今回は M5StickC-Plus というデバイスを使って MQTT 通信を試しました。M5Stack というシリーズの小型のデバイスです。
こういう感じの↓

この M5StickC-Plus 向けのコードもリポジトリに含まれているのでコード全文を見たい方はそちらをご覧ください。
以下は要点を絞って解説していきます。(ただ、主題は Unity なので軽く解説します)
/// /// セットアップ /// void setup() { Serial.begin(115200); M5.begin(); // 中略 // 接続 ensureWifi(); ensureMqtt(); }
setup 内で Wi-Fi と MQTT ブローカーへの接続を確認しています。
/// /// MQTT ブローカーへの接続処理 /// bool mqttConnect() { mqtt.setServer(BROKER_URL, BROKER_PORT); mqtt.setCallback(onMqttMessage); mqtt.setBufferSize(MQTT_BUF_SIZE); mqtt.setKeepAlive(MQTT_KEEPALIVE_SEC); mqtt.setSocketTimeout(15); // Last Will and Testament(LWT) const char* willTopic = TOPIC; const char* willMsg = "{\"status\":\"offline\"}"; bool willRetain = false; Serial.printf("[MQTT] Connecting to %s:%d ...\n", BROKER_URL, BROKER_PORT); M5.Lcd.fillScreen(BLACK); M5.Lcd.setCursor(0, 0); M5.Lcd.println("Connecting to MQTT..."); bool ok = mqtt.connect(clientId.c_str(), nullptr, nullptr, willTopic, 1, willRetain, willMsg, true); if (ok) { Serial.println("[MQTT] Connected."); // 購読 if (mqtt.subscribe(TOPIC, 1)) { Serial.printf("[MQTT] Subscribed: %s\n", TOPIC); M5.Lcd.fillScreen(BLACK); M5.Lcd.setCursor(0, 0); M5.Lcd.println("Connected MQTT."); } else { Serial.println("[MQTT] Subscribe failed"); } } else { Serial.printf("[MQTT] Connect failed. State=%d\n", mqtt.state()); } return ok; }
上記はブローカーへの接続処理です。接続後は subscribe 関数を使って購読します。
接続時にコールバック関数を指定しているため、メッセージを受信した際は以下の関数が呼ばれます。
/// /// MQTT の受信コールバック /// void onMqttMessage(char* topic, byte* payload, unsigned int length) { Serial.printf("[MQTT] Message arrived: topic=%s, len=%u\n", topic, length); String msg; msg.reserve(length); for (unsigned int i = 0; i < length; i++) { msg += (char)payload[i]; } Serial.printf("[MQTT] Payload: %s\n", msg.c_str()); M5.Lcd.fillScreen(BLACK); M5.Lcd.setCursor(0, 0); M5.Lcd.printf("[MQTT] Payload: %s\n", msg.c_str()); }
引数にトピックやペイロードが含まれているため、それを元に処理を行います。今回はサンプルなので画面に表示するのみです。
最後に、Arduino では loop 関数を用いてループ処理を書きます。この中で、ブローカーからの通知を受け取るために mqtt.loop() を実行します。
/// /// ループ /// void loop() { M5.update(); // 接続維持 ensureWifi(); ensureMqtt(); if (mqtt.connected()) { mqtt.loop(); } }
簡単ですが、以上が M5StickC-Plus 向けの実装となります。
最後に
MQTTnet ライブラリのお陰で、Unity でも簡単に MQTT を扱うことができました。 最近は AI グラが多数登場してきています。AI と XR デバイスとの相性もよく、IoT デバイスを用いることでさらに AI の活用の幅が広がると思っています。
今後は AI だけじゃなく、IoT 関連も積極的に追っていこうと思います。
再掲となりますが、よかったらぜひ、ご自身でも色々動かしてみてください。
IL2CPP が出力した C# の文字列の扱いを探ってみた
この記事は Unity のアドベントカレンダー 5 日目の記事です。
はじめに
この記事に需要があるか分からないですがw IL2CPP が書き出した内容を分析することにハマっていて色々見ていく中で、文字列の扱いが面白かったのでまとめました。
普段、書き出された Xcode プロジェクトの中身ってあんまり見ないかと思います。特に IL2CPP が出力した部分は分かりづらい表記になっていますし。
例えば C# で定義したクラスはこんな感じで表現されます。
// C# 側で定義したフィールドと同じ名前のフィールドが定義されている。 struct ScriptTest_t4722BADE3094615A9E6B31588AB39A9699182583 : public MonoBehaviour_t532A11E69716D348D8AA7F854AFCBFCB8AD17F71 { int32_t ____age; float ____weight; String_t* ____name; }; // こちらはコンストラクタ相当の処理をする関数 IL2CPP_EXTERN_C IL2CPP_METHOD_ATTR void ScriptTest__ctor_m292EB1426D8DEE94DCFD8136DE806F79853C20D5 (ScriptTest_t4722BADE3094615A9E6B31588AB39A9699182583* __this, const RuntimeMethod* method) { static bool s_Il2CppMethodInitialized; if (!s_Il2CppMethodInitialized) { il2cpp_codegen_initialize_runtime_metadata((uintptr_t*)&_stringLiteralF6C15C8F610D71383C2B2F4070B2867C10F83B38); s_Il2CppMethodInitialized = true; } { __this->____age = ((int32_t)20); __this->____weight = (60.0f); __this->____name = _stringLiteralF6C15C8F610D71383C2B2F4070B2867C10F83B38; Il2CppCodeGenWriteBarrier((void**)(&__this->____name), (void*)_stringLiteralF6C15C8F610D71383C2B2F4070B2867C10F83B38); MonoBehaviour__ctor_m592DB0105CA0BC97AA1C5F4AD27B12D68A3B7C1E(__this, NULL); return; } }
関数やクラス、構造体など様々なものに謎の文字列が付与されているのが分かります。これは C# 側の名前空間などで区切られたものをフラットにした際に、名前の衝突などが起こらないようにするために付与されたハッシュ値です。
ぱっと見ただけではなにをしているか分かりづらいので余計、中身を見ようとは思わないでしょう。
今回はその中でも文字列の扱いが面白かったので処理を追っていきたいと思います。
ちなみに文字列の処理だけを抜粋すると以下の部分になります。
static bool s_Il2CppMethodInitialized; if (!s_Il2CppMethodInitialized) { il2cpp_codegen_initialize_runtime_metadata((uintptr_t*)&_stringLiteralF6C15C8F610D71383C2B2F4070B2867C10F83B38); s_Il2CppMethodInitialized = true; } __this->____name = _stringLiteralF6C15C8F610D71383C2B2F4070B2867C10F83B38;
最初になにやら初期化処理をしてから使用していますね。実はこの初期化処理が大事で、最初の段階では文字列フィールドの _stringLiteralF6C15C8F610D71383C2B2F4070B2867C10F83B38 には文字列が設定されていません。
大枠の理解
ひとつずつ処理を見ていく前に、大枠の流れを理解しておきましょう。
上でも書いたように、文字列のフィールドには最初は文字列そのものは設定されていません。ではなにが設定されているのかというと「文字列を取り出すための情報」がエンコードされたものが設定されています。
具体的にどんな形で定義されているかを見てみると以下のようになっています。
// Il2CppMetadataUsage.c というファイルで定義されている . . . String_t* _stringLiteralBD09A3DAA622349FF74F11ECD6DDD1B297C3FDF2 = (String_t*)(uintptr_t)2684368525; String_t* _stringLiteralC54E9E453CAA8F5DCE5559DA89197E4A9C9B3C54 = (String_t*)(uintptr_t)2684368527; String_t* _stringLiteralF6C15C8F610D71383C2B2F4070B2867C10F83B38 = (String_t*)(uintptr_t)2684368529; // <- これが上で紹介した文字列フィールドに設定される元 String_t* _stringLiteral561357A43AFC43D221B9F230B04E836DD73101EB = (String_t*)(uintptr_t)2684368531; String_t* _stringLiteralF27F76F2C38EFE61B0AD0108BAD5476B6693C4F2 = (String_t*)(uintptr_t)2684368533; . . .
こんな感じで、C# 側で使用している文字列やその他多くの情報が一覧で定義されています。そして見てもらうと分かる通り、実際に設定されている値は文字列そのものではなく (uintptr_t)2684368529 という謎の数値です。
これをどう使うかを詳細に見ていくのが今回の記事です。が、ここでは大まかに処理の流れを概観します。
- 文字列変数のポインタを初期化関数に渡す
- 初期化関数内では、ポインタから値を取り出してそこに埋め込まれている情報を元に文字列を検索する
- 検索で見つかった文字列への参照を、文字列変数の参照先に再設定する
特に (2) については、謎の数値だった部分から値を取り出して処理していくことになります。結論から言うと、変数の種類やデータへのオフセットなどの情報が「エンコード」された数値となります。
初期化の開始
ということでさっそく処理を見ていきましょう。
冒頭でも載せましたが改めて初期化処理を見ていきます。
static bool s_Il2CppMethodInitialized; if (!s_Il2CppMethodInitialized) { il2cpp_codegen_initialize_runtime_metadata((uintptr_t*)&_stringLiteralF6C15C8F610D71383C2B2F4070B2867C10F83B38); s_Il2CppMethodInitialized = true; }
s_Il2CppMethodInitialized は static 変数なので一度初期化されたあとは 2 回目は処理されません。そして実際に初期化処理をしているのは il2cpp_codegen_initialize_runtime_metadata という関数です。
ちなみにこの関数は、出力されたプロジェクトの以下の場所に保存されています。
<XCODE_PROJECT_ROOT>/Il2CppOutputProject/IL2CPP/libil2cpp/codegen/il2cpp-codegen.cpp
処理を辿っていくと
void* il2cpp::vm::MetadataCache::InitializeRuntimeMetadata(uintptr_t* metadataPointer); void* il2cpp::vm::GlobalMetadata::InitializeRuntimeMetadata(uintptr_t* metadataPointer, bool throwOnError) IL2CPP_DISABLE_TSAN;
を呼び出すようになっていて、最終的に初期化処理をしているのは il2cpp::vm::GlobalMetadata::InitializeRuntimeMetadata となります。
データの取り出し
まずは il2cpp::vm::GlobalMetadata::InitializeRuntimeMetadata の定義を見てみましょう。( Il2CppOutputProject/IL2CPP/libil2cpp/vm/GlobalMetadata.cpp で定義されている)
// This method can be called from multiple threads, so it does have a data race. However, each // thread is reading from the same read-only metadata, so each thread will set the same values. // Therefore, we can safely ignore thread sanitizer issues in this method. void* il2cpp::vm::GlobalMetadata::InitializeRuntimeMetadata(uintptr_t* metadataPointer, bool throwOnError) IL2CPP_DISABLE_TSAN { // This must be the only read of *metadataPointer // This code has no locks and we need to ensure that we only read metadataPointer once // so we don't read it once as an encoded token and once as an initialized pointer uintptr_t metadataValue = (uintptr_t)os::Atomic::ReadPtrVal((intptr_t*)metadataPointer); if (IsRuntimeMetadataInitialized(metadataValue)) return (void*)metadataValue; uint32_t encodedToken = static_cast<uint32_t>(metadataValue); Il2CppMetadataUsage usage = GetEncodedIndexType(encodedToken); uint32_t decodedIndex = GetDecodedMethodIndex(encodedToken); void* initialized = NULL; switch (usage) { case kIl2CppMetadataUsageTypeInfo: initialized = (void*)il2cpp::vm::GlobalMetadata::GetTypeInfoFromTypeIndex(decodedIndex, throwOnError); break; case kIl2CppMetadataUsageIl2CppType: initialized = (void*)il2cpp::vm::GlobalMetadata::GetIl2CppTypeFromIndex(decodedIndex); break; case kIl2CppMetadataUsageMethodDef: case kIl2CppMetadataUsageMethodRef: initialized = (void*)GetMethodInfoFromEncodedIndex(encodedToken); break; case kIl2CppMetadataUsageFieldInfo: initialized = (void*)GetFieldInfoFromIndex(decodedIndex); break; case kIl2CppMetadataUsageStringLiteral: initialized = (void*)GetStringLiteralFromIndex(decodedIndex); break; case kIl2CppMetadataUsageFieldRva: const Il2CppType* unused; initialized = (void*)GetFieldDefaultValue(GetFieldInfoFromIndex(decodedIndex), &unused); { const size_t MappedFieldDataAlignment = 8; // Should match System.Reflection.Metadata.ManagedPEBuilder.MappedFieldDataAlignment IL2CPP_ASSERT(((uintptr_t)initialized % MappedFieldDataAlignment) == 0); } break; case kIl2CppMetadataUsageInvalid: break; default: IL2CPP_NOT_IMPLEMENTED(il2cpp::vm::GlobalMetadata::InitializeMethodMetadata); break; } IL2CPP_ASSERT(IsRuntimeMetadataInitialized(initialized) && "ERROR: The low bit of the metadata item is still set, alignment issue"); if (initialized != NULL) { // Set the metadata pointer last, with a barrier, so it is the last item written il2cpp::os::Atomic::PublishPointer((void**)metadataPointer, initialized); } return initialized; }
ちょっと処理が多いので少しずつ紐解いていきましょう。まず冒頭で行っている処理を見ていきます。
uintptr_t metadataValue = (uintptr_t)os::Atomic::ReadPtrVal((intptr_t*)metadataPointer); if (IsRuntimeMetadataInitialized(metadataValue)) return (void*)metadataValue;
最初に行っているのは、渡されたポインタの実際の値を取り出しています。冒頭で紹介した「謎の数値」を取り出しているわけですね。
そして次に行っているのが初期化済みかどうかの判定。この判定もトリックがあるので見ていきましょう。
コードを抜粋すると、以下のように処理されています。
template<typename T> static inline bool IsRuntimeMetadataInitialized(T item) { // Runtime metadata items are initialized to an encoded token with the low bit set // on startup and when initialized are a pointer to an runtime metadata item // So we can rely on pointer alignment being > 1 on our supported platforms return !((uintptr_t)item & 1); }
この処理が行っているのは、対象の値の 1 ビット目にフラグが立っているかのチェックです。ですが、なぜこれが可能なのでしょうか。1 ビットでも変化すれば値がおかしくなるかもしれませんよね。
しかしこれは、システムの特性が絡んできます。ここで評価しているのは「文字列を参照するポインタ」です。ポインタはアドレスを保持する変数ですね。そしてこのアドレスは、32 ビットマシンであれば 4 バイト単位、64 ビットマシンであれば 8 バイト単位にデータが一定の境界に揃えられ(アラインメント)ています。
※ ここで言うアラインメントは、32 / 64 ビットマシンなどの CPU アーキテクチャの特性に基づいて行われます。OS は主にページ単位(数 KB 程度)でメモリを割り当てますが、それより細かい粒度(今回の 4 / 8 バイト)での整列は、コンパイラやリンカ、メモリアロケータ(malloc, newなど)といったプログラムにより行われます。これらは CPU 特性を考慮した効率化の観点から、変数や構造体、関数などを一定のバイト境界に揃えることを意味しています。(akeit0 さんに指摘いただき、誤解を招きそうだったので補足しました)
言い換えると、アドレスの値はきれいにそろっている、ということです。つまり、下位のビットは常に整列されるため 0 になるわけです。
例えば 32 ビットマシンの場合で考えて、スタートのアドレスが 0b00000 始まりとして次のアドレスは 4 バイト目、つまり 0b00100 が次のアドレスとなる。同様にその次は 0b01000, 0b01100, 0b10000 … と常に下位 2 ビットは 0 になっているのが分かります。
そのため、下位のビットは不要なわけなんですね。見なくても分かる。なぜなら整列されていることが前提になっているから。 なのでそこに目をつけて、ここをフラグとして利用している、というわけなんですね。
もしここのフラグが立っていたら 初期化済みとして 未初期化として判定している、というわけです。
(すみません、判定処理を少し勘違いしていました。正しくは「未初期化」かどうかの判定になります)
データをデコード
最初にも書いた通り、文字列変数( String_t* 型)にはエンコードされた数値が設定されているのでした。それをデコードしている処理を見てみましょう。
uint32_t encodedToken = static_cast<uint32_t>(metadataValue); Il2CppMetadataUsage usage = GetEncodedIndexType(encodedToken); uint32_t decodedIndex = GetDecodedMethodIndex(encodedToken);
まず最初に、取り出した値を uint32_t 型にキャストします。そして最初に取り出すデータが Il2CppMetadataUsage です。このあとの処理で、このタイプに応じて処理が変わります。
実装も見てみましょう。
static inline Il2CppMetadataUsage GetEncodedIndexType(EncodedMethodIndex index) { return (Il2CppMetadataUsage)((index & 0xE0000000) >> 29); }
これが行っているのは、引数に渡された index 変数から上位 3 ビットを取り出すことです。( index は前段の「謎の数値」)
0xE0000000 を 2 進数表現すると 0b11100000000000000000000000000000 です。上位 3 ビットだけ取り出し、それを 29 ビット右にシフトすることで上位 3 ビットの値を得ています。そしてこの 3 ビットに Il2CppMetadataUsage の値が設定されているというわけですね。
さて続いて GetDecodedMethodIndex 関数についても見ていきましょう。
static inline uint32_t GetDecodedMethodIndex(EncodedMethodIndex index) { return (index & 0x1FFFFFFEU) >> 1; }
この 0x1FFFFFFE を 2 進数表現にすると 0b00011111111111111111111111111110 です。上位 3 ビットが 0 なのは前段で使用している部分だからですね。そしてこのマスクと & を取ってさらに右に 1 ビットシフトさせた値が、文字列データへのインデックス(オフセット)の値となります。
文字列データを得る
エンコードされたデータから、Usage と インデックスを取り出すことができました。このデータを用いて、実際に文字列データを取り出す処理を見ていきましょう。
まず最初に Usage によってスイッチします。今回は kIl2CppMetadataUsageStringLiteral なので GetStringLiteralFromIndex 関数が実行されます。
switch (usage) { // ... 略 ... case kIl2CppMetadataUsageStringLiteral: initialized = (void*)GetStringLiteralFromIndex(decodedIndex); break; // ... 略 ... }
関数の実装は以下です。
static Il2CppString* GetStringLiteralFromIndex(StringLiteralIndex index) { if (index == kStringLiteralIndexInvalid) return NULL; IL2CPP_ASSERT(index >= 0 && static_cast<uint32_t>(index) < s_GlobalMetadataHeader->stringLiteralSize / sizeof(Il2CppStringLiteral) && "Invalid string literal index "); if (s_StringLiteralTable[index]) return s_StringLiteralTable[index]; const Il2CppStringLiteral* stringLiteral = (const Il2CppStringLiteral*)((const char*)s_GlobalMetadata + s_GlobalMetadataHeader->stringLiteralOffset) + index; Il2CppString* newString = il2cpp::vm::String::NewLen((const char*)s_GlobalMetadata + s_GlobalMetadataHeader->stringLiteralDataOffset + stringLiteral->dataIndex, stringLiteral->length); Il2CppString* prevString = il2cpp::os::Atomic::CompareExchangePointer<Il2CppString>(s_StringLiteralTable + index, newString, NULL); if (prevString == NULL) { il2cpp::gc::GarbageCollector::SetWriteBarrier((void**)s_StringLiteralTable + index); return newString; } return prevString; }
最初の方は変数のアサートなどですね。そして s_StringLiteralTable というテーブルに値がすでに存在している場合はそれを返しています。これは、このあとの処理で得られた文字列をテーブルに書き込み、以後の処理をスキップするための処置です。
実際に文字列データを取得しているのは以下の部分です。
const Il2CppStringLiteral* stringLiteral = (const Il2CppStringLiteral*)((const char*)s_GlobalMetadata + s_GlobalMetadataHeader->stringLiteralOffset) + index;
最初の行で行っているのは、なにかしらのデータのアドレスに文字列リテラルのオフセットを加えた位置に、さらに、前段で求めた index を足した位置を文字列として取り出しています。
ここを少し深堀りしましょう。 GlobalMetadata の名前から推測できるように、グローバルに保存されたメタデータが存在していて、そこから適切にオフセットさせることで文字列を取り出しています。そしてこのメタデータは実はバイナリファイルとして保存されているデータを読み込んだものへの参照となっています。
文字データの所在
上の stringLiteral 変数が参照している文字列を出力したところ以下のような文字列の塊でした。おそらく、C# 側で使われている文字列がすべて連結された状態で保存されており、そこからオフセットと文字列の長さを利用して文字列を取り出しているものと思われます。
"edoelelasticAnimationIntervalMselasticityeleelemelementelement-nameelementSelectorelementTypeelementsellipsisembedPackageemoji-fallback-supportemojiFallbackSupportenen-USenable-rich-textenableCompilationCachingenableRichTextenableValidityChecksenabledenabledInHierarchyenabledSelfencodedDataencoderFallbackencodingendendIndexendIndex cannot be greater than startIndex.enterenumTypeenumType must not be null and it must be an Enum typeenvenvoyInfoequalseraeraseresescapeeteueuc-cneuc-jpeuc-kreventCounteventDataeventPtreventPtr is NULL but eventCount is != 0eventTypeevt.isPropagationStoppedexexceptionexceptionObjectexcludeFromFocusRing should only be set on composite roots.expectedexportShaderVariantsexprextentsextraPaddingeyezff1f10f11f12f13f14f15f2f3f4f5f6f7f8f9fIsMarshalledfafa-IRfalsefccfec2b7369466d88502a9dd38505f4fcd9651ded40425995dfa6aeb78f1f1cfeatureNamefifieldCountfilfilefileNamefilePathfillfilterfirebrickfirstfirstLayoutNamefirstListfirstStatePtrfirstVisibleCharacterfixationPointfixed-item-heightfixed-pane"...
実際、ここの処理で取り出そうとしている文字列は edo で、出力した文字データの冒頭は確かに edo となっていることが分かります。ここから 3 文字取り出せば晴れて目的の文字列が手に入る、というわけですね。
上記のバイナリファイルは以下に保存されていました。
<IPA_APP>/Data/Managed/Metadata/global-metadata.dat
実際にこのバイナリファイルの中から文字列を出力してみたところ、上記と同じ文字列の塊が見つかりました。
また GlobalMetadata.cpp にはこのメタデータを読み込む処理が書かれており、確かに s_GlobalMetadata がその参照を保持していました。
bool il2cpp::vm::GlobalMetadata::Initialize(int32_t* imagesCount, int32_t* assembliesCount) { s_GlobalMetadata = vm::MetadataLoader::LoadMetadataFile("global-metadata.dat"); if (!s_GlobalMetadata) return false; // 後略 }
これで目的の文字列を見つけることが出来ました。
テーブルへ保存
最後に、取得した文字列をテーブルに保存し、そののちに文字列の参照を返して処理は終了です。
Il2CppString* newString = il2cpp::vm::String::NewLen((const char*)s_GlobalMetadata + s_GlobalMetadataHeader->stringLiteralDataOffset + stringLiteral->dataIndex, stringLiteral->length); Il2CppString* prevString = il2cpp::os::Atomic::CompareExchangePointer<Il2CppString>(s_StringLiteralTable + index, newString, NULL);
取得した文字列の参照と文字数を用いて新しい Il2CppString* を生成し、それを前の値と比較します。が、ここではそもそも比較対象が NULL なので常に新しい値がテーブルに書き込まれます。
参照の書き換え
さぁ本当の最後の処理です。前段までで文字列を生成し、それをテーブルに保存してその参照を得ることができました。今回の目的は、元の文字列変数の参照先を本当の文字列への参照へ切り替えることだったことを思い出してください。
それを行っているのが以下の部分です。最初に取得した変数のポインタに対して、今回取得した参照( initialized )で上書きしているのが分かります。
if (initialized != NULL) { // Set the metadata pointer last, with a barrier, so it is the last item written il2cpp::os::Atomic::PublishPointer((void**)metadataPointer, initialized); }
これで以後は対象の変数 _stringLiteralF6C15C8F610D71383C2B2F4070B2867C10F83B38 はちゃんと文字列を参照するようになります。
さいごに
だいぶ回りくどい実装になっていますが、おそらくメモリ効率やセキュリティ的な観点からメリットがある実装なんだと思います。 調べる前はそのまま文字列が埋め込まれているのかと思っていたので、最初は謎の数値が保存されている変数を見て困惑しました。 が、処理が分かってくると色々な工夫があってとても学びのありました。
冒頭でも書いたように、この知識がなにかの役に立つかは不明ですが、もし誰かの参考になれば幸いです。
ECSを使ってTextMesh Proの文字を大量に描画する

前回の記事では、ECS自体の使いどころやそもそもなぜ高速化するのかという点について書きました。
記事の中で紹介した動画はTextMesh Proの文字を利用して大量に文字を空間に表示するというものでした。
こんなやつ↓
文字を表示するMeshをQuadのものに統一してBatch Group化の効率を上げて描画してみたら、80,000文字でも余裕で60FPS以上出た。プロファイラ見ると250FPSくらいの速度出てる。#Unity #ECS pic.twitter.com/yNcbk69Ukd
— edom18@XR / MESON CTO (@edo_m18) 2024年4月7日
概要
今回はこのTextMesh Proの文字をECSで大量に描画する方法について書いていこうと思います。
今取り組んでいるプロジェクトで文字を大量に表示する必要があるため、ECSが利用できそうだったので実装してみました。
ちなみに先に注意点を書いておくと実はTextMesh Proそのものを描画しているわけではありません。実際にはQuadなMeshに対してTextMesh Proの文字のテクスチャアトラスを利用して描画しています。
具体的に言うと、TextMesh Proの持っているグリフというフォントに関する情報を利用してUVを算出して描画するということをしています。
なので今回はTextMesh Proの文字をどうやって表示したか、どう動かしているかについて書いていこうと思います。
今回の記事で解説している内容はGitHubにもアップしてあるので、実際に動作するものを見たい方はリポジトリをクローンして見てください。
TextMesh ProのテクスチャアトラスのUVを算出する
冒頭でも書いたように既存のTextMesh Proの文字をそのままECSで動かすことはできません。今回の実装はTextMesh Proの Glyph を用いてテクスチャアトラスのUV位置を算出し、それをECS上で描画できるようにしたものです。
そのためTextMesh Proの Glyph データからUVなどを算出する方法について解説します。
Glyphについて知る
TextMesh Proでは Glyph (グリフ)の情報を用いてテキストの描画を行っています。まずはこのグリフについて理解します。
グリフとは
モリサワのサイトから引用すると以下のように説明されています。
字体とほぼ同義語ですが、記述記号やスペースなども含めたものを指します。
慣用的にはデータとしての字体を指す場合に使われることもあります。これらの文字と記号類を集めたものがグリフセットと呼ばれるもので、これは文字セットや文字コレクションとほぼ同義と考えてよいでしょう。
つまり、文字をレンダリングする際に必要となるデータ、という感じですね。
TextMesh Proのグリフを使ったメッシュ作成のコード断片を見るとなんとなくイメージがわくと思います。
// TMP_Character型のデータからGlyphを取得する Glyph glyph = tmpCharacter.glyph; // 中略 float x0 = -glyphWidth * 0.5f; float x1 = glyphWidth * 0.5f; float y0 = -glyphHeight * 0.5f; float y1 = glyphHeight * 0.5f; Vector3[] vertices = new[] { new Vector3(x0, y0, 0), new Vector3(x0, y1, 0), new Vector3(x1, y1, 0), new Vector3(x1, y0, 0), };
こんな感じで Glyph 情報から文字の幅や高さ、またそれ以外でもカーニングや表示位置など様々な情報を得ることができます。つまり、文字を記述するための情報が得られる、というわけです。
※ 上記のコード例はUVではなく、文字のサイズなどに合わせたメッシュを生成するコードの一部です。今回の描画には直接的には関係ありません。
Glyphから情報を抜き出す
グリフ情報で様々な情報を得ることができることが分かりました。これらの情報を利用して、テクスチャアトラスのUV位置を算出します。
UVを算出する
さっそく、グリフ情報からUVの値を算出しましょう。
ただ、この算出に当たって注意点があります。通常、UVは各頂点ごとに設定されます。Quadのような形状であれば都合4つのUVの値が必要となります。しかし今回はメッシュを生成せず、デフォルトのQuadメッシュを利用するため頂点ごとにUVの値を設定することができません。そのため、少しだけ工夫が必要になります。
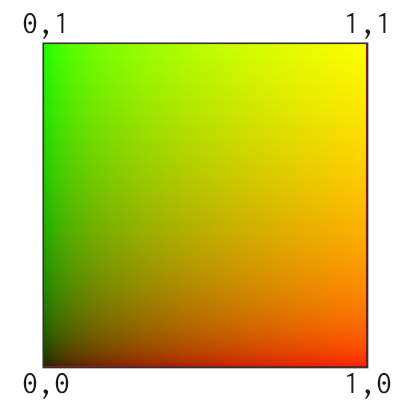
まず情報を整理すると、Quadのメッシュは左下が 0, 0、右上が 1, 1 となるUV値を持っています。図示すると以下のような値を持っています。
この値を加工してテクスチャアトラスのUVに合うようにできれば達成できそうです。
イメージとしては正方形を、望みの長方形に変形(縮小)した上で、テクスチャアトラスの該当位置まで移動させれば達成できそうですね。
次の画像がオフセットとスケールを調整するイメージです。ここでは「悟」という字に対して計算を行おうとしています。 ここでのゴールは、この「悟」という部分の赤い矩形の位置・サイズにぴったり重なるようにUVを加工することです。順に手順を見ていきましょう。

左下からX Offsetだけ右に移動し、Y Offsetだけ上に移動すると、「悟」の字の位置に原点( 0, 0 )が移動しますね。

文字サイズはそのままグリフ情報の幅と高さが使えます。そしてこれがそのままスケール値となります。
例えばスケールの値が横 0.05、縦 0.08 とした場合、Quadの4つのUVの値すべてに掛けて上げるとそれぞれ以下のようになります。(疑似コードで示します。左下から時計回りに値を設定していると仮定します)
float2 uv0 = new float2(0.0f * 0.05f, 0.0f * 0.08f); float2 uv1 = new float2(0.0f * 0.05f, 1.0f * 0.08f); float2 uv2 = new float2(1.0f * 0.05f, 1.0f * 0.08f); float2 uv3 = new float2(1.0f * 0.05f, 1.0f * 0.08f); // それぞれの値は以下になる。 // uv0 = ( 0.0, 0.0) // uv1 = ( 0.0, 0.08) // uv2 = (0.05, 0.0) // uv3 = (0.05, 0.08)
ちゃんと望みの値が得られていることが分かりますね。あとはこれに、前述のオフセットを足してやれば無事、テクスチャアトラスの文字をサンプリングするUVが得られる、というわけです。
この前提を元にUV値を算出している計算が以下です。
// グリフ情報を取得 Glyph glyph = tmpCharacter.glyph; // グリフのUVを計算 float rectWidth = glyph.glyphRect.width; float rectHeight = glyph.glyphRect.height; float atlasWidth = fontAsset.atlasWidth; float atlasHeight = fontAsset.atlasHeight; float rx = glyph.glyphRect.x; float ry = glyph.glyphRect.y; float offsetX = rx / atlasWidth; float offsetY = ry / atlasHeight; float uvScaleX = ((rx + rectWidth) / atlasWidth) - offsetX; float uvScaleY = ((ry + rectHeight) / atlasHeight) - offsetY; float4 uv = new float4(offsetX, offsetY, uvScaleX, uvScaleY);
ポイントはそれぞれの値の算出に、テクスチャアトラスのサイズを利用して正規化している点です。これによって適切にオフセットとスケールが求まります。
求めたこの値を使って、QuadのUVを加工することでテキストをECSでレンダリングすることができるようになります。
以下は、その計算を行っているShader Graphの様子です。

算出したUVのスケールの値を、Quadのスケールに乗算したあと、最後にオフセットを加算したものを最終のUVとしている様子です。
カスタムのUVをマテリアルに反映させる
UVの値を求め、それを利用するシェーダを準備することはできましたが、各文字のQuadごとに異なるUVを設定しなければなりません。通常の、MonoBehaviour なオブジェクトであれば個別にマテリアルに値を設定したり、あるいは MaterialPropertyBlock を使って設定することができます。しかし、ECSではそうした方法が使えません。
ではどうするのかというと、ECS側でオブジェクトごとに値を設定する方法が用意されているのでそれを利用します。
以下がそのドキュメントです。
シェーダ側の準備
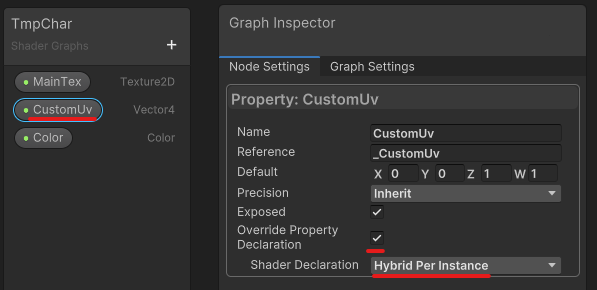
ドキュメントに沿って方法を解説していきます。まずはシェーダ側の準備です。Shader Graphのプロパティの設定に Override Property Declaration という項目があります。これをまずオンにします。すると Shader Declaration という項目が設定できるようになるので、これを Hybrid Per Instance に変更します。
今回はカスタムのUVの値をオーバーライドしたいので CustomUv の設定でこれを行っています。これを設定しているのが以下の図です。
シェーダの設定は以上です。
カスタムUV用のコンポーネントを用意する
次に準備するのはコンポーネントです。ECSではコンポーネント、つまりデータが中心に存在するため、こうしたデータ周りはコンポーネントが担います。そしてECSでは、前述のマテリアルのオーバーライドを実現する方法を用意してくれているので、それに従ってコンポーネントを定義します。
大事な点は2点で、その他のコンポーネントと同様に IComponentData インターフェースを実装しつつ、さらに MaterialProperty 属性を付与する点です。属性の引数にはオーバーライドしたいプロパティ名を指定します。
具体的には以下のようになります。(抜粋ではなく、これはコード全文です)
using Unity.Entities; using Unity.Mathematics; using Unity.Rendering; [MaterialProperty("_CustomUv")] public struct CustomUvData : IComponentData { public float4 Value; }
値は、Shader Graphで定義したものと同じ型を指定します。(ここでは float4 )
そして MaterialProperty 属性の引数には _CustomUv を指定しています。あれ、 CustomUv じゃないの? と思われた方もいるかもしれませんが、設定の画像を見てもらうと Reference という項目の設定が _CustomUv になっているのが分かると思います。これは実際にシェーダで利用される変数名、ということなわけですね。なのでこれを指定します。
コンポーネントをEntityに追加する
最後に、定義したコンポーネントをEntityに登録します。登録はその他のコンポーネントとまったく同じです。
CustomUvData uvData = GetCustomUvData(index);
entityManager.AddComponentData(entity, uvData);
CustomUvData の生成処理は前述のUV算出のところで説明したものです。あとはそれをEntityManagerを通して登録してやればOKです。これをマテリアルに適用する処理はECS側のシステムが自動で行ってくれるため、特に開発者側でなにかをする必要はありません。
文字サイズを設定する
最後に計算するのは文字サイズを設定することです。今回利用しているのはデフォルトのQuadメッシュです。これは1m x 1mのサイズの面になるのでそのままだとかなり大きいポリゴンになってしまいます。
またそれ以外にも、本来は文字ごとにメッシュのサイズが異なります。例えば文字の A や x、! ではメッシュサイズが異なります。
ポリゴン形状を可視化するとこんな感じです。

この違いを各Quadに適用するのがここで解説する内容です。
グリフからメッシュのスケールを計算する
UVの計算で行ったのと似たようなことをします。UVの場合はテクスチャの位置とスケールを求めていました。今回はグリフからメッシュのサイズ、つまりQuadのスケールを計算します。
// フォントサイズ private float FontSizeToUnit => _fontSizeInCm * 0.01f; // ------------------- // グリフ情報を取得 Glyph glyph = tmpCharacter.glyph; // グリフの幅と高さを計算 float toUnit = FontSizeToUnit * (1f / fontAsset.faceInfo.pointSize); float glyphWidth = glyph.metrics.width * toUnit; float glyphHeight = glyph.metrics.height * toUnit; return new float3(glyphWidth, glyphHeight, 1f);
冒頭のフォントサイズは、デフォルトだと1m x 1mと巨大なので、それを補正( * 0.01f )しつつ、SerializeField で指定されたフォントサイズの大きさに調整するものです。例えばフォントサイズを 24 とした場合は実際には24cmの大きさになる、という具合です。
幅と高さの計算では、フォントサイズに対してフォントフェイスの持っているポイントサイズの逆数を掛けることで、続く幅などの値を正規化しています。( glyph.metrics.width などはフォントフェイスサイズになっているため)
そして最終的に幅と高さに対して前述の toUnit を掛けることで想定したサイズが求まります。
ここで求めた値はメッシュのサイズですが、適用するQuadは 1 x 1 のサイズなので、結果的にそのままこのサイズがスケールの値となるわけです。
以上で文字周りの生成、計算が終わりました。
次に、これらのメッシュを描画する手順について見ていきましょう。
Entityの描画はRenderMeshArrayを使う
まずはEntityを作成します。
World world = World.DefaultGameObjectInjectionWorld; EntityManager entityManager = world.EntityManager; Entity entity = entityManager.CreateEntity(); entityManager.SetName(entity, $"TextMeshEntity {index.ToString()}");
ECSのシステムそのものの解説はここでは割愛しますが、基本的な生成フローです。ECSのワールドからEntityManagerを取得し、それを利用してEntityを作成しています。
次に、生成したEntityに、描画するための設定を行っていきます。
※ そもそもECSは計算効率を最大化する目的なので必ずしもすべてのECSが描画されるとは限りません。そのため、描画したい場合は専用のコンポーネントなどを適切に設定する必要があるわけです。
RenderFilterSettings filterSettings = RenderFilterSettings.Default; filterSettings.ShadowCastingMode = ShadowCastingMode.Off; filterSettings.ReceiveShadows = false; RenderMeshDescription renderMeshDescription = new RenderMeshDescription { FilterSettings = filterSettings, LightProbeUsage = LightProbeUsage.Off, }; RenderMeshArray renderMeshArray = new RenderMeshArray(new[] { _material }, new[] { _mesh });
まずはコンポーネントの設定に必要なデータの定義から。
冒頭の RenderFilterSettings と RenderMeshDescription は描画に関する設定項目です。影を落とすか、Light Probeの影響は、などを設定しています。
その次にある RenderMeshArray がオブジェクト自体の設定になります。今回は Mesh も Material もひとつだけ設定していますが、配列で指定することで複数のメッシュとマテリアルをひとつにまとめて設定することができます。
最後は描画するEntityの設定において重要な RenderMeshUtility.AddComponents メソッドです。これは、描画に必要なコンポーネントを適切に設定してくれるヘルパーメソッドです。
RenderMeshUtility.AddComponents(
entity,
entityManager,
renderMeshDescription,
renderMeshArray,
MaterialMeshInfo.FromRenderMeshArrayIndices(0, 0));
RenderMeshUtility のクラスコメントを見ると以下のように書かれています。
/// Helper class that contains static methods for populating entities /// so that they are compatible with the Entities Graphics package. /// エンティティを実装するための静的メソッド含むヘルパークラス。 /// これによりEntities Graphicsパッケージに適合させることができる。
このユーティリティの AddComponents メソッドを通して描画に必要なコンポーネントが設定されます。適切にコンポーネントが設定されたEntityがある場合、ECSのシステム側で自動的に描画まで行ってくれます。これで文字が画面に表示されるようになりました。
RenderMesh と RenderMeshArray
ECSの描画について調べていく際、 RenderMesh を利用するということが書かれている記事もあり混乱しました。特に、見出しにある RenderMeshArray は配列を示唆することから、ひとつのEntityを描画するのに冗長なのでは、と思ってしまったのが混乱の元でした。
結論から言うと RenderMesh は現状ではどうやら非推奨となっており、 RenderMeshArray を利用するのが正規の方法のようです。なぜ配列を利用するのかは、そもそもECSを利用するモチベーションである「大量にオブジェクトを処理する」という観点から考えると自明です。
つまり、描画に関するコストを最小限にしたいという思想があり、そのためにメッシュを配列で持ち、それを切り替えることでGPUのステートの変更を最小限にする、ということを実現するためだと思われます。
ちなみに参考にした記事から引用させてもらうと以下のように書かれていました。
私が機能を見落とした可能性は否定できませんが、 以前まで使用されていたInstancing無しの描画クラスであるRenderMeshについて以下のような記述があり、サポートがされていないようでした。
// RenderMesh is no longer used at runtime, it is only used during conversion. // At runtime all entities use RenderMeshArray.そのため、オブジェクトがEntity化されると自動的にプログラム側はDOTS Instancingの適用条件を満たすということになります。 Shader側は別途条件を満たすために処理を追加する必要があります。
とのことなので、基本的に RenderMeshArray を使っておけば問題ないでしょう。
文字を動かすシステムを作成する
最後は文字を動かすシステムについて見ていきます。
システムの詳細についてはここでは割愛します。システムの実装方法やデータの取り回しについては前回の記事を参照してください。ここでは、今回作成したシステムそのものについてだけ解説します。
文字の動きを制御するジョブ
まず最初に見るのは、今回の文字を動かしている要でもあるジョブについてです。ECSでもC# Job Systemを使ってワーカースレッドで処理することができます。基本的に ISystem を実装したシステムであればジョブシステム化することも容易でしょう。
ECS用のジョブとして IJobEntity というインターフェースが用意されています。今回はこれを実装します。
今回の文字の動きを制御しているジョブの実装は以下のようになっています。
[BurstCompile] partial struct TmpUpdateJob : IJobEntity { public double Time; private void Execute([EntityIndexInQuery] int index, ref MeshInstanceData meshData, ref LocalToWorld localTransform) { double move = math.sin((Time * meshData.TimeSpeed + index) * math.PI) * meshData.MoveSpan; // index is just offset for the time. float3 position = meshData.Position + new float3(move); float angleSpeed = 0.005f; float angle = (float)math.sin(Time * meshData.TimeSpeed * angleSpeed * math.PI) * 360f; quaternion rotation = math.mul(meshData.Rotation, quaternion.RotateY(angle)); localTransform.Value = float4x4.TRS(position, rotation, meshData.Scale); } }
冒頭の [BurstCompile] 属性によってバーストコンパイラによるコンパイルを指示しています。バーストコンパイラでコンパイルすることができれば相当な高速化が見込めます。積極的に使っていきましょう。
実装自体は Execute メソッドを実装するだけです。しかし実は IJobEntity インターフェース自体はなにも宣言していない、ある意味マーカーのようなインターフェースとなっています。おそらくですが、ECSの大半がソースジェネレータによってコードが自動生成されるため、インターフェース周りも同じような制御になっているのでしょう。
そのため、 Execute メソッドの定義は必須となっていますが、引数に指定するものは柔軟に指定することができます。特に、そのジョブで利用するデータ型を指定することで、実行時に適切に対象データをシステムが提供してくれるようになります。
今回の例で言えば以下の部分ですね。
void Execute([EntityIndexInQuery] int index, ref MeshInstanceData meshData, ref LocalToWorld localTransform);
第一引数の [EntityIndexInQuery] 属性は、クエリの中でのEntityの位置を示しています。これを利用すると、コンピュートシェーダのスレッドIDのような使い方ができます。
そして続く第二、第三引数には実際に利用するコンポーネントの型を指定しています。今回はこのふたつだけのコンポーネントが必要でしたが、もしこれ以外にも必要な場合は引数として定義してやると、ECSのシステムが引数に対象コンポーネントを渡してくれるようになります。
値を更新するデータの場合は ref を、参照だけ(つまり読み取りだけ)する場合は in を指定します。あとはメソッドの実装部分で該当データを使って処理を行うだけです。今回は MeshInstanceData に初期値が入っているので、適当にSin関数などで回転や移動をしているだけです。
実際のプロジェクトではもっと意味のある処理をする必要がありますが、どうやって実装していくかがなんとなくイメージできるかと思います。
システムの全体を実装する
ジョブの実装が終わったので、あとはこのジョブを利用するシステムを実装します。今回のシステムではトランスフォーム、つまりメッシュの姿勢を制御する前に値を更新したいため、 [UpdateBefore()] 属性を指定して、トランスフォームの更新システムの前に処理されるように指示しています。
using Unity.Burst; using Unity.Entities; using Unity.Mathematics; using Unity.Transforms; [UpdateBefore(typeof(TransformSystemGroup))] public partial struct TmpSystem : ISystem { public void OnCreate(ref SystemState state) { state.RequireForUpdate<MeshInstanceData>(); state.RequireForUpdate<LocalToWorld>(); } [BurstCompile] public void OnUpdate(ref SystemState state) { var job = new TmpUpdateJob() { Time = SystemAPI.Time.ElapsedTime, }; job.ScheduleParallel(); } }
OnCreate メソッドでは、必要とするコンポーネントの種類を指定することができるため、今回は MeshInstanceData と LocalToWorld コンポーネントを持つEntityを対象とすることをシステムに伝えています。
そして OnUpdate で実際にジョブを生成し、スケジュールします。
システムの全体像は以上です。描画に関してはECSの RenderMeshSystem が自動で行ってくれるため、これ以上の実装は必要ありません。
まとめ
最終的に、テキストの色指定なども加えて以下のような見た目になりました。(iPhone 15 Proで動かしても60FPSを達成できています)
ECS使って160,000文字表示してみた。iPhone15Proでも余裕で60FPS出た。#Unity #ECS pic.twitter.com/aqGkaSNKNN
— edom18@XR / MESON CTO (@edo_m18) 2024年4月9日
ECSを利用すると、メモリアクセスの効率、ひいてはデータ転送の効率がいかに遅いかに気付かされます。処理負荷というとつい、計算のアルゴリズムや大量のオブジェクトの問題に目が行きがちですが、一番のボトルネックは「データ転送速度」というわけなのですね。
まったくの余談ですが、PolySpatialを用いたApple Vision Pro向けアプリ開発ではカスタムシェーダがほぼ使えず、Compute Shaderを用いたパーティクルなどの描画が行えません。現状ではECSもレンダリングできないのですが、シェーダのカスタムよりは実現可能性が高いのかな、と思っているので密かにECSに期待しています。
ぜひみなさんもECSで大量のオブジェクトをコントロールする楽しさに触れてみてください。
ECSの仕組みを理解し、使いどころを把握する

もともとECS/DOTSには興味があって知りたいと思っていたのですが、なかなか実プロジェクトで使うタイミングがなく放置してしまっていたのですが、今開発している中で利用できそうな箇所があったので、改めて入門して、備忘録的に学んだことをまとめていきたいと思います。
ちなみに、ECSを使ってTextMesh Proの文字を大量に(80,000文字)出してみたら、余裕で60FPS出る状態でした。(PCではありますが、プロファイラで見ると4msくらいしかかかってなかったので全然まだ余裕があった)
文字を表示するMeshをQuadのものに統一してBatch Group化の効率を上げて描画してみたら、80,000文字でも余裕で60FPS以上出た。プロファイラ見ると250FPSくらいの速度出てる。#Unity #ECS pic.twitter.com/yNcbk69Ukd
— edom18@XR / MESON CTO (@edo_m18) 2024年4月7日
概要
本記事ではECSの内容を概観し、全体像を把握して使い所を把握することを目的に書いています。ECSの実装方法については簡易的なサンプルを示しつつ、ECSのコアであるデータ指向の部分について、なぜ高速化するのか、どういうところで真価を発揮するのかについて書いていきたいと思います。
ECSとは
ECSは「Entity / Component / System」の頭文字を取ったものです。これは、EntityとComponentでオブジェクトとデータを定義し、Systemによって振る舞いが処理されることからついている名前のソフトウェアアーキテクチャです。ECS自体の概念はUnity特有のものではなく、効率的な処理を目的としたソフトウェア開発で採用されているアーキテクチャです。
なぜECSアーキテクチャだと高速化するのか
ではなぜ、ECSアーキテクチャだと処理が高速化するのでしょうか。その謎を紐解くには、現代のコンピュータの状況を考える必要があります。2024年時点でのCPUは大体1GHz~5GHzのクロック周波数で動きます。ざっくり計算で、1GHzだとすると1秒間に10億回の演算ができることになるので、1クロックあたりの時間は 1 / 1,000,000,000 = 0.000000001秒 となり、1ナノ秒となります。
かなり高速に演算することができることが分かりますね。では次に、メモリからデータを取得するための時間はどれくらいかかるか見てみましょう。以下の記事から引用すると、
各種メモリ/ストレージのアクセス時間,所要クロックサイクル,転送速度,容量の目安 #コンピュータアーキテクチャ - Qiita
下記記事によると,前述のInetl Core i9-13900K からアクセスした 実測値だと86.8ns でした.
【Hothotレビュー】6GHzのマイルストーンに達したCore i9-13900KSの性能をチェック - PC Watch
と書かれていて、メインメモリからの転送時間は実に 86.8ns もかかっています。もちろん状況によって変化することはありますが平均的には60~80nsくらいでしょう。とすると、1GHz程度のCPUから見ても実に60~80倍以上遅い結果となっています。
このことから、コンピュータによる計算における最大のボトルネックはCPUとメモリ間のデータ転送と見ることができます。
ECSはCPUのキャッシュを最大活用する
前述のように、CPUとメモリ間でのデータのやり取りが大きなボトルネックになることが分かりました。しかし一般的に、CPUにはメインメモリ以外にもL1, L2, L3というキャッシュ機構が用意されています。L1から順にCPUに近いキャッシュメモリとなります。前述の記事からさらに引用させてもらうと各キャッシュのアクセスに必要なクロックは以下のように記載されています。
1次キャッシュメモリ(level 1 (L1) cache memories) について,2022年で最も高性能な部類に入るCPUである,Intel Core i9-13900Kでは,4クロックサイクル でアクセスできます.
2次キャッシュメモリ(level 2 (L2) cache memories) について,2022年で最も高性能な部類に入るCPUである,Intel Core i9-13900Kでは,10クロックサイクル でアクセスできます.
3次キャッシュメモリ(level 3 (L3) cache memories) について,2022年で最も高性能な部類に入るCPUである,Intel Core i9-13900Kでは,34クロックサイクル以内,10.27ナノ秒以内 でアクセスできます.
一番近いL1キャッシュでは実に4サイクル(CPUが4回演算する時間)でデータを取り出すことができます。1GHzのCPUであれば 4ns ですね。メインメモリと比較して20倍以上高速です。しかし、CPUに近いキャッシュメモリほど容量が小さく、一度に保存できるデータ量が制限されてしまいます。記事によると2022年時点でもL1キャッシュは64KB程度しかありません。メインメモリが最近ではGB単位あることを考えると相当に小さいことが分かります。
メインメモリを本棚、キャッシュを机として考えてみる
キャッシュを利用するイメージを例え話で考えてみましょう。
L1キャッシュは自身の机で、メインメモリは本棚だと考えてみます。こう考えると、メインメモリにアクセスするのは本棚に本(資料)を取りに行くこと、L1キャッシュに保存するのはそれを机に置くこと、と考えることができます。
こう考えると、本棚から持ってくる本がデータで、机に置いておく本がキャッシュされたデータ、ということになりますね。
さてでは、どうやったら効率的に本を利用できるでしょうか。言い換えると、どうやったら本棚との往復を最小限にできるでしょうか。まず思いつくのは一度の往復で本をたくさん持ってくることです。しかしそれだけだと、使わない本ばかりを持ってきてしまっても意味がありません。なので、できるだけたくさんの使える本を持ってきて机に置いておくことが重要ですね。
CPUとメインメモリ・キャッシュ間の関係もまったく同じなので、できるだけ、メインメモリから取得したデータを効率よく扱えるようにしたい、と思うのは自然な発想でしょう。
そしてまさにこの「データのキャッシュ性を高める」ことを実現しているのがECSというアーキテクチャなわけです。
ECS向けのデータ構造
なぜECSが高速に動くのか、その理由がメモリのキャッシュ効率を最大化することだ、というのは前述した通りです。ではECSではどのようにこれを実現しているのでしょうか。
データ構造を定義するArchetype
ECSではデータはC、つまりComponentが担います。UnityのECSではEntityの持つComponent群を Archetype というタイプごとに管理をするようになっています。アーキタイプは構造のタイプというですね。ここで言う構造は言い換えると「どんなコンポーネントを持っているエンティティか」となります。
例えばコンポーネントの種類が A B C と3種類あるとしましょう。そしてEntityは任意のコンポーネントを持つことができます。例えば、Entity1はコンポーネントA, B、Entity2はコンポーネントA, B, Cを持つ、という具合です。
そしてこの「コンポーネント A, B, Cを持つ」という事実を Archetype として定義することで、あとからデータを取得しやすくしているわけです。
公式の動画で分かりやすい図が紹介されていたので引用させていただきます。

データを実際に配置するChunk
前述の Archetype はいわば概念です。「こういうコンポーネント郡を持っているエンティティにラベルを貼る」という感じですね。しかし概念だけではコンピュータは動きません。特に、メモリのキャッシュ効率を最大化することが目的なので、メモリレイアウトにはかなり気を使う必要があります。そしてこの「どういうふうにデータをメモリ上に配置するか」という実装に関するものが Chunk となります。
このチャンクの仕組みを視覚的に説明してくれている動画がUnityの公式にあります。
上の動画から、該当部分のアニメーションを抜き出すと以下のように説明されています。(動画ではKeijiroさんが詳しく解説してくれているので、興味がある方はぜひ観てみてください)
まずは、一般的なオブジェクト指向な場合のメモリレイアウト、メモリアクセスの様子です。

次に、ECSによるデータ指向なメモリレイアウト、メモリアクセスの様子です。
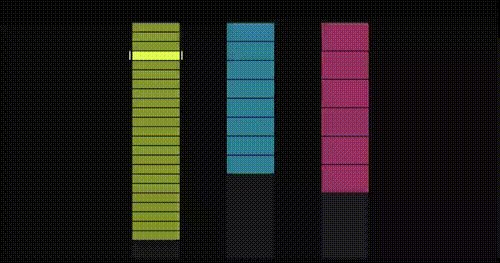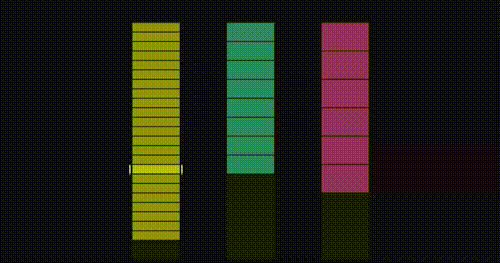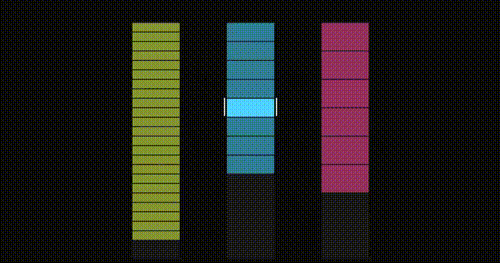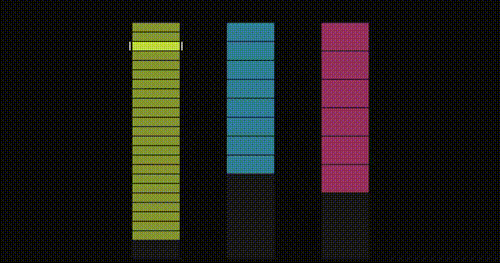
前者はメモリ上にデータがバラバラに点在しているためアクセスがあちこちに飛んでいるのが分かります。一方後者はデータがメモリ上に連続的に並んでおり、効率よくアクセスできていることが見て取れます。
CPUのアーキテクチャは通常、メインメモリアクセスが発生した場合、キャッシュラインという単位でまとめてデータを取得し、それをキャッシュに載せます。CPUのアーキテクチャでは「空間的局所性」と「時間的局所性」に基づいてこうしたキャッシュを利用しようとします。
ここで言う局所性とは、演算対象のデータの近く(空間)のものはすぐに使われる、一度アクセスしたデータは近く(時間)アクセスされる、ということをベースとして考えられています。つまり、ECSのデータ指向なメモリレイアウトはこの考え方に非常にマッチしている、というわけですね。メモリ上に連続してデータが並んでおり、かつ処理もそのデータ単位でまとめて行ってしまおう、というのがコンセプトなのですから。
前述のように、メモリアクセスは演算からすると数十倍もの開きがあります。これを最適化できれば、単純計算で処理が数十倍になる、というわけですね。(とはいえ、そこまで単純な話ではありませんが)
メモリレイアウトを深堀りする
さて、局所性に基づいてメモリレイアウトが決まるということを話しました。では実際、 Chunk はどういう形でデータを保持しているのでしょうか。
Unity公式動画の図を再掲します。
以下が公式の動画です。興味がある方はこちらも観てみてください。
上記の図をイメージしつつ、中身を見ていきましょう。
ChunkはArchetypeごとのデータとEntityの配列を持つ
前述したように、ECSでは Archetype と呼ばれる型によってチャンクが決まり、そのチャンクの中にコンポーネントが配列として保持されるということでした。
そしてそのChunk内にはコンポーネントだけではなく、Entityのリストも保持されるようです。以下のフォーラムでのやり取りから抜粋します。
Entities
All entities are stored in a single EntityData struct array. Entity.index is the index into this array and EntityData provides a direct address to its Components. Is an Entity struct also stored in the chunk so it can refer back to the entities array? This is what EntityArray is generated from?
As a user can store Entity, am I right in assuming that the items in the entities array never change position? If you add 1000 entities and remove the first 999, that last entity is still going to be at the 1000th index?
特に太字の部分ですね。これは、エンティティ構造体がChunk内に含まれるか、という問いです。そしてそのEntity構造体から、 EntityArray にアクセスできるか、という質問です。
この質問に対するUnityの中の人の回答は以下でした。
Yes. In fact we have essentially an Entity as the 0 component. This is what EntityArray is using internally.
Entity 自体は実際に 0 コンポーネントとして保持しているとのこと。よく考えてみればある意味で自明ですね。チャンク内にコンポーネントデータの配列があったとしても、そのコンポーネントがどのエンティティのものなのか分からなければ使いようがないですからね。
実装方法
以上で概念的なところは終了です。以下からは実際にどうやって実装していくかについて見ていきます。ただ、ここでは簡単に状況を整理するだけにとどめます。細かな実装方法や実際に活用する方法については別の記事にゆずります。あくまで概観することを目的にしています。
データを定義する
まず最初に説明するのはデータについてです。データ指向とも呼ばれているのでデータが中心に存在します。UnityのECSではデータは IComponentData インターフェースを実装することになっています。
ちなみにコンポーネントのコンセプトとして、ドキュメントにはこう記載されています。
Use the
IComponentDatainterface, which has no methods, to mark a struct as a component type. This component type can only contain unmanaged data, and they can contain methods, but it's best practice for them to just be pure data. If you want to create a managed component, you define this as a class. For more information, refer to Managed components.
太字の部分を見てみると、インターフェースを利用する意味はただのマーカーとしてのようですね。
具体的には以下のように定義します。
public struct SampleTransformData : IComponentData { public float3 Position; public quaternion Rotation; public float3 Scale; }
IComponentData インターフェースを実装し、姿勢制御に必要な3つの要素を持つデータを定義している様子です。注目してもらいたいのは struct で定義している点です。基本的にECSでは struct、つまり構造体を使って構築していくのがベストプラクティスです。
理由は前述したメモリレイアウトの問題にあります。クラスを利用してしまうと、これはマネージドな領域にデータが確保されてしまうため、結果的にECSの最大のメリットであるメモリ効率性に影響が出てしまいます。
しかし構造体で定義した場合、その配列はメモリ上に連続的に配置され、ECSのコンセプトであるメモリアクセスの効率化につながるというわけです。
データはstruct / class両方で定義できる
ただ、現実問題として必ずすべてを構造体で、というのはむずかしい局面もあるでしょう。その場合にはクラスで定義することが可能となっています。これをマネージドコンポーネントと呼び、このコンポーネントではマネージドなデータ、つまりクラスの参照を持つことができます。
ドキュメントから引用すると以下のようになります。
public class ExampleManagedComponent : IComponentData { public int Value; }
ただし当然デメリットもあり、メモリレイアウトの問題もそうですが、こうしたデータは BurstCompiler でコンパイルすることができなかったりするので使用は一部にとどめておくのがいいと思います。
システムを構築する
次に解説するのはECSの「S」、Systemについてです。(ECSの最初のEntityが最後なんかい、と思うかもしれませんが、後述しますがEntityはあまり書くことがないのでこの順番にしています)
ECSにおけるシステムは、一言で言い表すならば「データを処理する担当者」です。ECSの世界では(実際、 World というクラスが存在する)様々なシステムが多数存在し、それぞれが自身の役割をまっとうしていきます。
データは基本的に独立しており、それぞれが独自に処理されても問題ない、言い換えると並列化可能なものが多くあるということです。
もちろん、レンダリングに必要なデータの更新などは先にしてから描画を行うなどの「順番」はあります。しかし、とあるシステムの処理に介入してなにかをする、ということはありません。そのため各システムを独立して実装し、結果として整合性が取れていればいいということになります。
以下のキャプチャはECSで実行されているシステムのリストです。Unity から始まるのはUnityが用意しているシステムです。中央やや下あたりに赤線を引いた場所がありますが、これは自分で作成したシステムです。

このように、様々なシステムが駆動して処理を行っているのが分かるかと思います。
システムはクエリを利用してデータを取得して処理する
大まかにシステムの処理がどういうフローになるかを概観しておきます。
システムは毎フレーム実行されます。MonoBehavior のように毎フレーム OnUpdate が呼び出されます。ここに処理を書いていくことになります。
そしてこの処理の中で、「自分が必要とするデータをクエリして取得」し「取得したデータを加工する」というのが大まかな流れになります。
ざっくりしたコード例は以下です。
public void OnUpdate(ref SystemState state) { float deltaTime = SystemAPI.Time.DeltaTime; foreach (var localTransform in SystemAPI.Query<RefRW<LocalToWorld>>()) { // do something } }
システムの実装方法は2種類
コンポーネントのところでも書きましたが、マネージド・アンマネージドの2種類に応じて実装方法が異なります。
アンマネージドなシステム
アンマネージドなシステムの場合は、コンポーネントと同様に struct で定義します。簡単な例を示すと以下のような形です。
public partial struct TmpSystem : ISystem { public void OnUpdate(ref SystemState state) { float deltaTime = SystemAPI.Time.DeltaTime; foreach (var localTransform in SystemAPI.Query<RefRW<LocalToWorld>>()) { // do something } } }
注目ポイントとして partial struct で定義をしているところです。これは、Unityエンジン側がソースジェネレータ機能を用いて他の必要な部分を自動生成するために partial が必要になっています。そして ISystem を実装することで自動的にシステムとして認識され、起動されるようになります。
マネージドなシステム
続いてマネージドなシステムです。マネージドシステムは SystemBase を継承することで実現します。
ドキュメントから一部引用すると以下のような形になります。
public partial class ECSSystem : SystemBase { protected override void OnUpdate() { // do something. } }
マネージドなシステムも同様に partial として定義する必要があります。それ以外は基本的に ISystem のものと同じです。大きな違いとしてはマネージドなオブジェクトを持てること、そしてバーストコンパイラを利用できないことが挙げられます。
しかしながら、ECSを利用するモチベーションはそのパフォーマンスの高さにあるため、できるだけ ISystem で実装するのがいいでしょう。
ドキュメントにも以下のように記載されています。
In general, you should use ISystem over SystemBase to get better performance benefits.
一般に、高いパフォーマンスを得るためには
SystemBaseではなくISystemを利用すべきです。
実際の実装例
次回の記事で書く予定の内容から、実際に実装したシステムのコードを例として示します。以下は、TextMesh Proの文字をメッシュ化してたくさん表示する、というのをECSで実現した際のコードです。なんとなく、どういう流れで処理をするのか分かると思います。
using Unity.Burst; using Unity.Entities; using Unity.Mathematics; using Unity.Transforms; public partial struct TmpSystem : ISystem { public void OnCreate(ref SystemState state) { state.RequireForUpdate<MeshInstanceData>(); state.RequireForUpdate<LocalToWorld>(); } [BurstCompile] public void OnUpdate(ref SystemState state) { float deltaTime = SystemAPI.Time.DeltaTime; double time = SystemAPI.Time.ElapsedTime; foreach (var (meshData, localTransform) in SystemAPI.Query<RefRW<MeshInstanceData>, RefRW<LocalToWorld>>()) { quaternion rotation = math.mul(meshData.ValueRW.Rotation, quaternion.RotateY(10f * deltaTime)); float3 position = meshData.ValueRW.Position; position += new float3(math.sin(time) * 0.1); meshData.ValueRW.Position = position; meshData.ValueRW.Rotation = rotation; localTransform.ValueRW.Value = float4x4.TRS(meshData.ValueRW.Position, rotation, meshData.ValueRW.Scale); } } }
OnCreateのタイミングで、どんなデータが必要かを通知できる
コードを見てみると OnCreate のタイミングで state.RequireForUpdate<T>() を実行しているのが分かります。これは、このシステムが要求するデータを示しています。そのため、現在のワールド内に該当のコンポーネントを持っているEntityがない場合は OnUpdate がスキップされます。
クエリで取得したデータを加工する
OnUpdate 内では SystemAPI を通してコンポーネントをクエリして取得し、取得されたコンポーネントに対して更新処理を行っている様子です。
このシステムの OnUpdate 内でまとめてデータを処理するために、メモリアクセス的に効率よく処理が行えている、というわけですね。さらにアンマネージドなコンポーネントを使っている場合は [BurstCompile] 属性を付与することでさらに高速に処理することができるようになります。
EntityはID
最後にECSの「E」であるEntityについてです。
Entity についてはあまり書くことがないと書いたのは、 Entity は実質ただの ID でしかないからです。
実際に実装内容を見てみると、実質的には Index と Version しかありません。(実際には IComparable<T> などのインターフェースを実装しているためメソッドは定義されていますが、前述のふたつの値を比較するなどの目的なので本質的には無視して問題ない内容となります)
以下は実際のコードから変数部分だけを抜き出したものです。
public struct Entity : IEquatable<Entity>, IComparable<Entity> { /// <summary> /// The ID of an entity. /// </summary> /// <value>The index into the internal list of entities.</value> /// <remarks> /// Entity indexes are recycled when an entity is destroyed. When an entity is destroyed, the /// EntityManager increments the version identifier. To represent the same entity, both the Index and the /// Version fields of the Entity object must match. If the Index is the same, but the Version is different, /// then the entity has been recycled. /// </remarks> public int Index; /// <summary> /// The generational version of the entity. /// </summary> /// <remarks>The Version number can, theoretically, overflow and wrap around within the lifetime of an /// application. For this reason, you cannot assume that an Entity instance with a larger Version is a more /// recent incarnation of the entity than one with a smaller Version (and the same Index).</remarks> /// <value>Used to determine whether this Entity object still identifies an existing entity.</value> public int Version; }
Index が実質的にIDになっており、このIDを利用してコンポーネントのデータを取得したり、ということが内部的に行われているわけです。
言い換えると、 MonoBehaviour な GameObject のように、オブジェクト自身がデータを持っているわけではない、ということさえ理解しておけば大丈夫です。
まとめ
ECSがなぜ高速に動くのか、その理由が分かったかと思います。
大事な点を再掲すると、
- メモリ効率が大事
- メモリレイアウトを工夫することで最適化
- データ単位で処理を行う「データ指向」アーキテクチャ
となります。
ざっくり言ってしまえば、効率的に管理できるようにデータをまとめて用意し、さらに効率的に処理できるようにシステムがまとめてデータを加工する、という流れを実現しているのがECSということができるでしょう。
さらに、本来は色々な制約があって実現するのがむずかしいBurstコンパイラ向けの設定が、仕組みに沿って実装するだけで簡単に実現できるというのも大きなポイントでしょう。
大量にオブジェクトを処理する必要があるようなプロジェクトの場合はぜひ導入を検討してみてください。
llama.cppをUnityで扱う

去年(2023年)の3月頃にChatGPTのAPIが公開されてから、AI熱が高まり最近では様々な生成AIが毎日のようにニュースになっています。
MESONでもAIには積極的に取り組んでいて、自分もとてもAIに興味があります。
生成AIでは特に大規模言語モデル(LLM)に興味があって、人生の中で一番ワクワクしているときかもしれません。
このLLM、うまく使えばかなり色々なことが実現できます。特に、ローカルで動くLLMが当たり前になってくると本当にSFの世界のような体験が作れるのでは、と期待しています。
そんなわけなので、ローカルで、特にスマホでLLMを動かすことにとても興味があり、かつ自分はUnityエンジニアなのでLLMをUnityアプリに組み込みたいなと考えていました。
そしてllama.cppという素晴らしいプロジェクトがあります。これは、Meta社が公開しているLlamaというオープンソースのLLMをC++で実装し、様々な環境で動かせるようにしてくれているリポジトリです。
その中でllamacpp.swiftという、iOS向けのプロジェクトがサンプルにあり、iOS実機で試すことができるようになっています。
幸いなことにこれはSwiftパッケージの形で提供されているため、これをビルドしてUnityに組み込む、というのが今回の記事の主題です。
実際に動かしてみたのが以下の動画です。
llamacppをUnityで動かすやつ。llamacpp.swiftにデフォルト設定されてるモデルだと、ネイティブアプリと同じ速度感だったので、やはりモデルの問題だった。ので、llamacppがUnityで動く環境は手に入れられたぞ#LLAMA #llamacpp #Unity #madewithunity pic.twitter.com/HVCNwwvGUV
— edom18@XR / MESON CTO (@edo_m18) 2024年2月26日
この組み込みを行う上で少しハマったのでそれを備忘録として残しておきます。
今回実装したものはGitHubに上げてあるので全体を見たい人は参考にしてください。
▼ Unity
▼ Xcode(llamacpp-wrapper)
※ モデルは小さなものでも1GB近くあったりするのでリポジトリには含まれていません。そのため、ご自身でダウンロードして Assets/StreamingAssets/models 内に配置してください。
今回利用したモデルはこちらのモデル(tinyllama-1.1b-1t-openorca.Q4_0.gguf)です。
Unityに組み込む準備
Unityに組み込むにあたり、Swiftパッケージをそのまま持って行くことはできません。また、開発の効率を考えるとUnity Editor上でも動かせる必要があります。ということで、macOS向けとiOS向けにパッケージをビルドし、双方で扱えるようにすることを目標とします。
iOS / macOS向けにビルドする
Swiftパッケージを両プラットフォーム向けにビルドするところから始めましょう。といっても、ビルドに関する記事は前回書いたので、ビルドの仕方そのものは前回の記事を参考にしてください。ここではllama.cppのビルドのみに焦点を絞って書きます。
llama.cppをラップするSwiftパッケージを作成する
llama.cpp自体はSwiftパッケージとして利用できる形になっていますが、本体はC++で実装されています。そのため、llama.cppのパッケージをそのままビルドしてもUnity側で扱える形になっていません。そこで、llama.cppをラップするパッケージを作成し、そのパッケージの依存先としてllama.cppを設定する、という形で実装を行います。
つまりこのパッケージの目的はllama.cppの機能をC#から利用できるようにインターフェースの役割を担います。
前回の記事でも、自作のSwiftパッケージを外部のパッケージに依存させる方法を書いているので詳細はそちらを参照ください。
まずはSwiftパッケージを新規作成(初期化)し、llama.cppを依存関係に追加します。
Swiftパッケージの作成は以下のようにコマンドを実行してください。
$ mkdir llama-wrapper $ cd llama-wrapper $ swift package init --type library --name llama-wrapper
上記コマンドを実行するとパッケージに必要なファイルなどが自動生成されます。その中でパッケージの情報を示す Package.swift があるので、必要な設定をしていきます。
具体的には以下を追加・修正します。
dependenciesにllama.cppを追加する- GitHub上の名前と一致しないので名前の指定
- ライブラリの
typeを.dynamicにして共有ライブラリとする - 対応Platformの指定を追加
最終的に以下のようになります。(必要な部分だけ抜粋)
let package = Package( name: "llamacpp-wrapper", platforms: [ .macOS(.v13), .iOS(.v16), .watchOS(.v4), .tvOS(.v14) ], products: [ .library( name: "llamacpp-wrapper", type: .dynamic, targets: ["llamacpp-wrapper"]), ], dependencies: [ .package(url: "https://github.com/ggerganov/llama.cpp.git", branch: "master"), ], targets: [ .target( name: "llamacpp-wrapper", dependencies: [ .product( name: "llama", package: "llama.cpp") ]), // 後略 }
Platformにはビルドの際に、対応バージョンなどによってエラーが発生するのでその下限に適合するように指定しています。
まずはビルドしてみる
現時点でビルドが通る状態になっているはずです。特に機能は実装していませんが、以下のコマンドを実行してそれぞれのプラットフォーム向けにビルドできるか確認しておきましょう。
▼ macOS向け
$ swift build -c release --arch arm64 --arch x86_64
macOS向けのビルドは自動的に .build フォルダにビルドされるので、もしFinderなどで見ている場合に不可視ファイルの可能性があるのでターミナルなどから開いてください。
▼ iOS向け
$ xcodebuild -scheme llama-wrapper -configuration Release -sdk iphoneos -destination generic/platform=iOS -derivedDataPath ./Build/Framework build
iOSの場合はビルド先フォルダを指定しているのでそのフォルダを開きます。
※ 前回のビルドの解説のところでも書いたのですが、生成直後のものをビルドしてもTestターゲット向けのビルドでコケるので、今回はひとまずコメントアウトして回避しています。
// .testTarget( // name: "llamacpp-wrapperTests", // dependencies: ["llamacpp-wrapper"]),
これでパッケージ作成の準備が整いました。以下から実際に実装をしていきます。
ラッパーを実装する
前段まででUnityに組み込む準備ができました。続いてllama.cppの機能をC#から呼び出すための処理などを追加していきます。
llama.cppの実装を呼び出す機能の実装
llamacpp.swift に含まれている実装をそのまま移植します。具体的には LibLlama.swift をコピーします。この実装は名前から推測できる通り、C++側の実装を呼び出し実際に推論などを行う実装が含まれています。
以下のように追加しました。
今回新規で追加するのは、この LibLlama.swift に実装されている LlamaContext クラスの処理をC#から呼び出せるようにするものです。
今回の実装は、 LibLlama.swift と同様にllama.cppに含まれていた LlamaState.swift の実装を参考にしました。
まずは今回実装したコード全文を載せます。その後、個別に解説します。
import llama import Foundation public typealias completion_callback = @convention(c) (UnsafeMutablePointer<CChar>) -> Void public class LlamaWrapper { let NS_PER_S = 1_000_000_000.0 var llamaContext: LlamaContext? var message: String = "" init() { } init(llamaContext: LlamaContext) { self.llamaContext = llamaContext } public func complete(text: String, completion: completion_callback) async -> Void { self.message = "" let t_start = DispatchTime.now().uptimeNanoseconds await self.llamaContext?.completion_init(text: text) let t_heat_end = DispatchTime.now().uptimeNanoseconds let t_heat = Double(t_heat_end - t_start) / NS_PER_S self.message += "\(text)" guard let llamaContext = self.llamaContext else { let faileMessage = strdup("Failed to create text.") completion(faileMessage!) return } while await llamaContext.n_cur < llamaContext.n_len { let result = await llamaContext.completion_loop() self.message += "\(result)" print(result) } let t_end = DispatchTime.now().uptimeNanoseconds let t_generation = Double(t_end - t_heat_end) / NS_PER_S let tokens_per_second = Double(await llamaContext.n_len) / t_generation await llamaContext.clear() self.message += """ \n Done Heat up took \(t_heat)s Generated \(tokens_per_second) t/s\n """ let messagePtr = strdup(self.message) completion(messagePtr!) } } @_cdecl("create_instance") public func create_instance(_ pathPtr: UnsafePointer<CChar>) -> UnsafeMutableRawPointer { let path = String(cString: pathPtr) do { let llamaContext: LlamaContext = try LlamaContext.create_context(path: path) let wrapper: LlamaWrapper = LlamaWrapper(llamaContext: llamaContext) return Unmanaged.passRetained(wrapper).toOpaque() } catch { let wrapper: LlamaWrapper = LlamaWrapper() return Unmanaged.passRetained(wrapper).toOpaque() } } @_cdecl("llama_complete") public func llama_complete(_ pointer: UnsafeMutableRawPointer, _ textPtr: UnsafePointer<CChar>, _ completion: completion_callback) -> Void { let llamaWrapper: LlamaWrapper = Unmanaged<LlamaWrapper>.fromOpaque(pointer).takeUnretainedValue() let text = String(cString: textPtr) Task { await llamaWrapper.complete(text: text, completion: completion) } }
ラッパークラスを実装
まずはラッパークラス( LlamaWrapper )を見ていきましょう。
ここの実装がまさに LlamaState.swift の実装を参考にしたものです。今回はあまり複雑なことはせず、C#から文字列を受け取り、それをもとにLLMで推論を行うだけのものになっています。
実際の推論については LlamaContext クラスで行うため、それを呼び出すラッパーとして実装しています。そのため、コンストラクタで LlamaContext のインスタンスを受け取って利用する形としています。
init(llamaContext: LlamaContext) { self.llamaContext = llamaContext }
生成過程については後述します。
続いて実際に推論する処理である complete メソッドを見ていきます。ここがまさに LlamaState.swift からの引用部分です。
public func complete(text: String, completion: completion_callback) async -> Void { self.message = "" let t_start = DispatchTime.now().uptimeNanoseconds await self.llamaContext?.completion_init(text: text) let t_heat_end = DispatchTime.now().uptimeNanoseconds let t_heat = Double(t_heat_end - t_start) / NS_PER_S self.message += "\(text)" guard let llamaContext = self.llamaContext else { let faileMessage = strdup("Failed to create text.") completion(faileMessage!) return } while await llamaContext.n_cur < llamaContext.n_len { let result = await llamaContext.completion_loop() self.message += "\(result)" print(result) } let t_end = DispatchTime.now().uptimeNanoseconds let t_generation = Double(t_end - t_heat_end) / NS_PER_S let tokens_per_second = Double(await llamaContext.n_len) / t_generation await llamaContext.clear() self.message += """ \n Done Heat up took \(t_heat)s Generated \(tokens_per_second) t/s\n """ let messagePtr = strdup(self.message) completion(messagePtr!) }
ここの処理が行っているのは各種時間計測と、 LlamaContext によって推論された文字列を結合していく処理になっています。
メインの処理はこの部分ですね。
while await llamaContext.n_cur < llamaContext.n_len { let result = await llamaContext.completion_loop() self.message += "\(result)" }
最終結果として利用する message プロパティに文字列を足し込んでいっているだけです。ちなみに非同期処理となるため、C#側へはコールバックを用いて結果を返すようにしています。
コールバックを使ってC#側で結果を受け取る
Swift側の非同期処理が挟まるため、結果を返すのにコールバックを用いています。コールバックの定義は以下のようになっています。
public typealias completion_callback = @convention(c) (UnsafeMutablePointer<CChar>) -> Void
上記で定義したコールバックのaliasを利用して関数の引数としてコールバックを受け取ります。
typealias の通り、 completion_callback を新しい型として利用できるように宣言しています。続く @convention(c) はC言語の関数呼び出し規約を適用するという意味です。
以下、ChatGPTに聞いて得られた回答です。
@convention(c): この属性は、関数ポインタがC言語の呼び出し規約を使用することを指定します。Swiftはデフォルトで自身の呼び出し規約を持っていますが、この属性を使用することで、C言語との相互運用が可能になります。特に、C言語のAPIと連携する場合や、C言語のライブラリをSwiftから使用する場合に重要です。
そしてこの型を利用して関数を受け取る関数を定義します。
public func llama_complete(_ pointer: UnsafeMutableRawPointer, _ textPtr: UnsafePointer<CChar>, _ completion: completion_callback) -> Void { }
こうすることで、実行完了後にC#側に結果を渡すことができます。
第一引数に UnsafeMutableRawPointer を受け取っていますが、これは LlamaWrapper クラスのインスタンスへのポインタです。C#から呼び出す際に指定しています。なぜこうする必要があるのかについては前回の記事を参考にしてください。
インスタンスの生成と取り回し
Swift側のクラスのインスタンスはポインタ経由でC#とやり取りするのが基本です。そのため、インスタンスの生成周りについて少しだけ解説しておきます。
インスタンスの生成処理は以下のようになっています。
@_cdecl("create_instance") public func create_instance(_ pathPtr: UnsafePointer<CChar>) -> UnsafeMutableRawPointer { let path = String(cString: pathPtr) do { let llamaContext: LlamaContext = try LlamaContext.create_context(path: path) let wrapper: LlamaWrapper = LlamaWrapper(llamaContext: llamaContext) return Unmanaged.passRetained(wrapper).toOpaque() } catch { let wrapper: LlamaWrapper = LlamaWrapper() return Unmanaged.passRetained(wrapper).toOpaque() } }
この関数がインターフェースとしてC#に公開されており、引数に文字列のポインタを受け取ります。これは推論を実行するモデルへのパスです。そのパスを渡して LlamaContext のインスタンスを生成します。生成時に失敗する可能性があるため try-catch していますが、本当であれば失敗時にエラーを通知する仕組みが必要ですが、今回は動かすことだけを目的にしているので細かい制御はしていません。もしエラーが発生したらコンテキストを持たない LlamaWrapper クラスを生成しているだけです。(なので当然、その場合は推論実行時にエラーになります)
無事、コンテキストが生成できたらそれを引数にして LlamaWrapper クラスのインスタンスを生成し、そのポインタを返します。前述の推論用関数の第一引数に渡ってくるのはこのインスタンスになります。
Swift側のクラスのインスタンス生成、それをC#で利用する方法についてのより詳細な内容は前回の記事を参照してください。
C#側の実装
次に、C#側でSwift側にコールバックを渡す方法について見ていきます。
まずは宣言を見てみましょう。
[UnmanagedFunctionPointer(CallingConvention.Cdecl)] private delegate void CompletionCallback(IntPtr resultPtr); [DllImport(kLibName, CallingConvention = CallingConvention.Cdecl)] private static extern void llama_complete(IntPtr instance, string text, IntPtr completion);
大事な点は2点。コールバックとして渡すための delegate の宣言時に UnmanagedFunctionPointer(CallingConvention.Cdecl) 属性を付与する点と、デリゲートそのものは IntPtr としてポインタで渡している点です。
実際に渡している処理を見てみましょう。
[MonoPInvokeCallback(typeof(CompletionCallback))] private static void StaticCallback(IntPtr resultPtr) { _instance.Callback(resultPtr); } private void Predict() { _completionCallback = StaticCallback; IntPtr completionPtr = Marshal.GetFunctionPointerForDelegate(_completionCallback); _gcHandle = GCHandle.Alloc(_completionCallback); llama_complete(_llamaInstance, _prompt.text, completionPtr); }
デリゲートとして渡すメソッドを定義しています。なお、IL2CPPの制約でインスタンスメソッドを渡すことができません。渡せるのはstaticメソッドのみなのでその点に注意です。
また定義時に [MonoPInvokeCallback(typeof(CompletionCallbac))] として属性を付与しています。P/Invokeとして利用できるようにするための処置ですね。
P/Invokeとは
P/InvokeはPlatform Invokeの略です。ドキュメントの説明を引用すると、
P/Invokeは、アンマネージドライブラリ内の構造体、コールバック、および関数をマネージドコードからアクセスできるようにするテクノロジです。P/Invoke APIのほとんどは
SystemとSystem.Runtime.InteropServicesの2つの名前空間に含まれます。これら2つの名前空間を使用すると、ネイティブコンポーネントと通信する方法を記述するツールを利用できます。
つまり、ネイティブ側とやり取りするための規約(API)ということですね。まさにネイティブ側から呼び出されるように設定するため、MonoPInvokeCallback 属性を付けているというわけです。
そして実際に呼び出す部分を見てみると、上記のstaticメソッドをデリゲート型の変数に設定し、それを Marshal.GetFunctionPointerForDelegate() を利用してポインタ( IntPtr )に変換しています。そしてそれを引数にしてSwift側の実装を呼び出す、という流れになっています。
Swift側の実装は前述の通りです。推論が終わったらその結果をコールバックで返してくれます。あとは受け取った結果をC#側で利用するだけですね。
実プロジェクトで使うには
今回紹介したのは、あくまでllama.cppをUnityで扱う点についてのみです。よく見るとstaticメソッドなため、コールバックした結果を、呼び出したインスタンス側で扱えません。
このあたりはllama.cppをどうやって使うのかの設計にも関わってきます。例えばllama.cppを呼び出すだけのシングルトン的なものを配置して、コールバックはそのインスタンスに登録してやり取りする、などです。ただその場合でも、受け取る側を特定するための準備が必要になるでしょう。
また、Swift側のインスタンスの破棄など実際に使うとなると様々な考慮が必要になります。なので、今回の実装を実プロジェクトでそのまま利用するのはむずかしいでしょう。ただ、利用する方法が分かっていればあとは設計次第なので、より実践的に使えるようにブラッシュアップしていく予定です。
最後に、実装を進める上でハマったポイントをメモしておきます。
ハマったポイント
以下は、今回の実装時にハマったポイントを記載しておきます。
llama.cppの実装を呼び出すとクラッシュする
最初、この実装を始める前に色々llama.cppでiOSネイティブアプリをビルドしたりして調査をしていました。そのときの master ブランチの状態ではUnityに持っていってもクラッシュしなかったのですが、最新版ではなぜかクラッシュするようになってしまいました。
Metal周りの初期化でエラーが出ているようなのですが、なにが原因かはまだ特定できていません。
ちなみに、クラッシュせずに実行できた状態のコミットハッシュは 5bf2b94dd4fb74378b78604023b31512fec55f8f でした。もしご自身で試す場合、同様のエラーが出た場合はこのコミットまで戻してから利用してみてください。
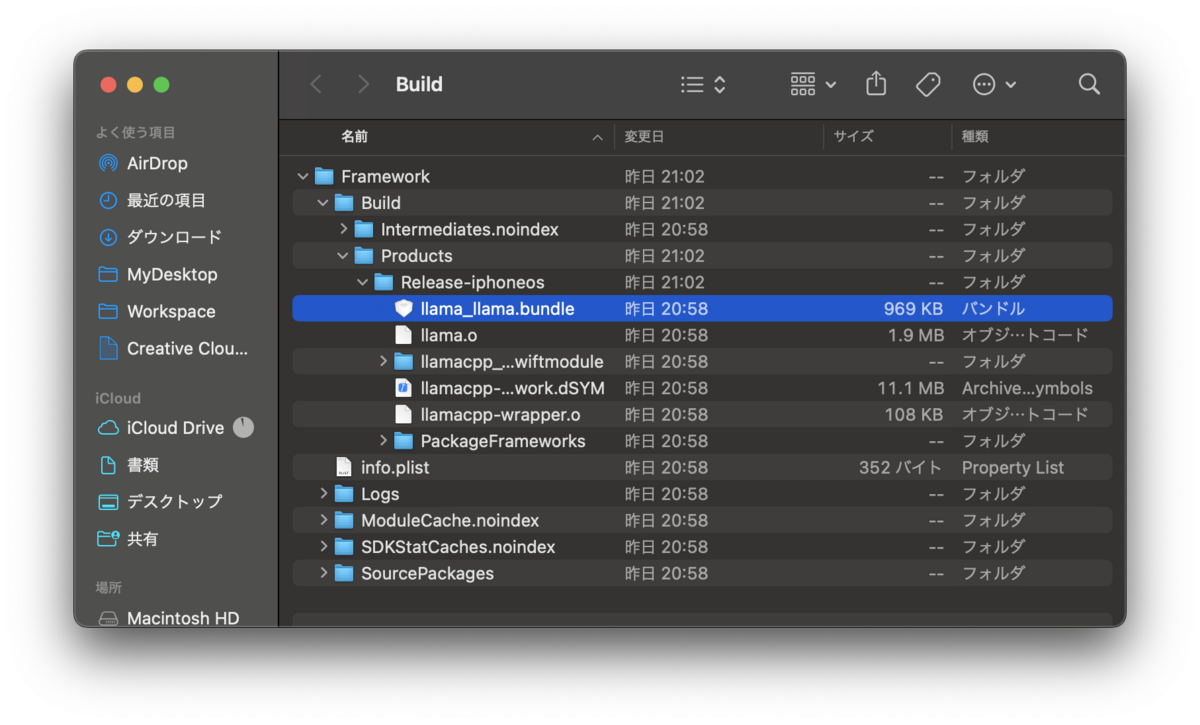
llama_llama.bundleが見つからない
上記クラッシュを回避したあと、無事にアプリが起動したのちに推論を実行したところ、 llama_llama.bundle が見つからないというエラーが発生しました。
これは、Swiftパッケージのビルド時に同時に生成されるバンドルファイルをプロジェクトに追加していなかったのが問題でした。なので、ビルドされたファイルの中にある llama_llama.bundle ファイルをUnityプロジェクトに追加する必要があります。(なお、macOS向けとiOS向けで内容が異なるので、それぞれのプラットフォーム向けに追加・設定する必要があります)
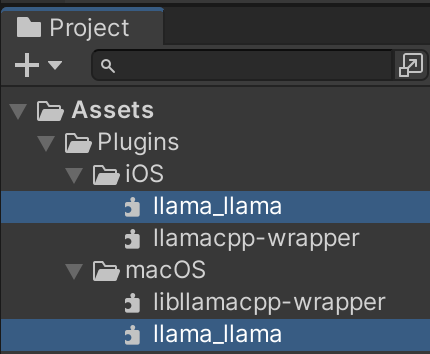
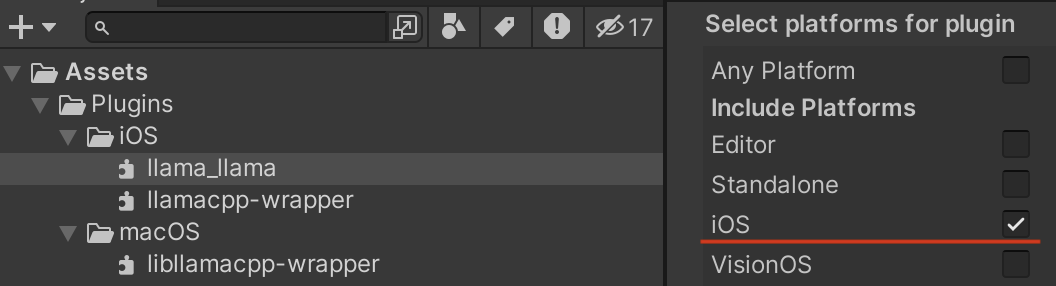
llama_llama.bundle はそれぞれのプラットフォーム向けになるようにインスペクタで設定する必要があります。
SwiftパッケージをビルドしてUnityで扱う

- 自作パッケージを作る
- パッケージをビルドする
- Swift側の実装を利用する
- Swiftのクラスを利用する
- Swift側の文字列(String)を扱う
- ネイティブ側からC#の関数を呼ぶコールバックの実装
- 依存のあるパッケージについて
- 注意点メモ
- 応用編
- まとめ
最近はAI関連のニュースが毎日のように飛び込んできますね。MESONでもXR x AIという形でAIにも注力しています。
ChatGPTを筆頭に、LLMはとんでもないスピードで発展しています。今ではローカルで、しかもモバイル上で動くLLMなんかも出てきたりしています。
今回は、iOSでパッケージを利用する方法についてまとめたいと思います。AIの話をしておいてなんでやねん、という感じですがiOS向けに利用できるLLMの環境としてllama.cppがあります。これ以外にもありますが、こうしたものを利用するにもUnityで扱える状態を作らないとならないので、そのために色々調査したものを備忘録としてまとめました。
ちなみにllama.cppのSwift実装はリポジトリの examples 内にあります。
■ サンプルプロジェクト
このブログ内で紹介しているサンプルプロジェクトをGitHubに上げてあるので、動作がうまくいかない場合などに参考にしてください。
自作パッケージを作る
ビルドしてUnityで利用するためのSwiftパッケージを作成するところから始めましょう。
パッケージ用に初期化する
まず、パッケージとなるディレクトリを作成し、以下のコマンドを使って初期化します。
$ mkdir SwiftPlugin $ cd SwiftPlugin $ swift package init --type library --name <PACKAGE_NAME> # 今回はSwiftPlugin
上記コマンドを実行すると以下のようにベースとなるファイルなどが生成されます。
Creating library package: SwiftPlugin Creating Package.swift Creating .gitignore Creating Sources/ Creating Sources/SwiftPlugin/SwiftPlugin.swift Creating Tests/ Creating Tests/SwiftPluginTests/ Creating Tests/SwiftPluginTests/SwiftPluginTests.swift
ここで生成された Package.swift をダブルクリックで開くとXcodeが起動し、パッケージとして認識されていることが確認できます。
今回はサンプルのためごく簡単なメソッドだけを実装してみます。
以下のコードを、デフォルトで生成される Sources/SwiftPlugin.swift に追加します。
@_cdecl("calc") public func calc(a: Int32, b: Int32) -> Int32 { return a + b }
定義の際の大事な点は関数に @_cdecl("関数名") 属性を付けることです。
cdeclについて
cdeclとは「呼び出し規約」と呼ばれるものです。呼び出し規約とは、コンピュータの命令セットアーキテクチャごとに取り決めとして定義されるもので、ABI(Application Binary Interface)の一部です。
Wikipediaから引用させてもらうと以下のように説明されています。
インテルx86ベースのシステム上のC/C++では cdecl 呼出規約が使われることが多い。cdeclでは関数への引数は右から左の順でスタックに積まれる。関数の戻り値は EAX(x86のレジスタの一つ)に格納される。呼び出された側の関数ではEAX, ECX, EDXのレジスタの元の値を保存することなく使用してよい。呼び出し側の関数では必要ならば呼び出す前にそれらのレジスタをスタック上などに保存する。スタックポインタの処理は呼び出し側で行う。
最終的に機械語に翻訳されたのち、関数呼び出しというのは「スタックに値を保持したあと、指定の場所に処理をジャンプさせる」という、かなり具体的な処理に変換されます。バイナリインターフェースの名前の通り、その際の「どうやってスタックに積むのか」などの取り決めを行うのがこの呼び出し規約です。
例えば、呼び出し側でスタックへ積む順番を間違えてしまうなどすると、呼び出される側で異なる位置の値を読み込んでしまうことになります。結果的に、引数が適切に渡らないなどの問題につながります。
今回はネイティブプラグインとして利用するため、この規約がなにに従っているのかを知る必要があるために @_cdecl という属性を付けている、というわけですね。C#のところでも解説していますが、C#側も「どう呼び出すか」というのを cdecl を指定して宣言しています。
パッケージをビルドする
あまり意味のない実装ですが、分かりやすさ優先です。さて、これをビルドしていきましょう。
Unityでの開発を想定しているため、iOS向けのビルドだけでなくmacOS向けのビルドも行い、Editor上で動くようにもしておきます。
macOS向けにビルドする
今回は共有ライブラリとしてビルドするため、 Package.swift を以下のように修正し、 type を .dynamic にしておきます。
// swift-tools-version: 5.9 // The swift-tools-version declares the minimum version of Swift required to build this package. import PackageDescription let package = Package( name: "SwiftPlugin", products: [ // Products define the executables and libraries a package produces, making them visible to other packages. .library( name: "SwiftPlugin", // typeを.dynamicにする type: .dynamic, targets: ["SwiftPlugin"]), ], targets: [ // Targets are the basic building blocks of a package, defining a module or a test suite. // Targets can depend on other targets in this package and products from dependencies. .target( name: "SwiftPlugin"), .testTarget( name: "SwiftPluginTests", dependencies: ["SwiftPlugin"]), ] )
macOS向けには以下のコマンドを利用してビルドします。コマンドを実行するのは Package.swift ファイルがあるフォルダ内です。
$ swift build -c release --arch arm64 --arch x86_64
実行すると .build フォルダが生成されその中にライブラリが入っています。(Finderで見ると . 付きフォルダのため見えない場合があります)
生成された中に .dylib の拡張子のものがあるのでこれを利用します。このファイルをUnityプロジェクトにインポートしてください。

macOS向けのビルドは以上です。
iOS向けにビルドする
次に、iOS向けにビルドしていきましょう。
iOS向けには xcodebuild コマンドを利用します。
$ xcodebuild -scheme <PACKAGE_NAME> -configuration Release -sdk iphoneos -destination generic/platform=iOS -derivedDataPath ./Build/Framework build
※ 今回のシンプルな状態でもTestターゲット向けに少しエラーが発生してしまいますが、Framework自体は生成されており、さらにちゃんと実機で動作する形になっています。なぜエラーが出るのか、どう解消したらいいのかについては追って調査予定です。
生成された SwiftPlugin.framework フォルダをUnityにインポートします。(フォルダごとです)
Unity上ではしっかりライブラリとして認識されます。(アイコンが変わる)
iOS向けライブラリはEmbed設定をする
iOS向けライブラリは Add to Embedded Binary のチェックを入れておく必要があります。
以上でiOS側の設定も完了です。
Swift側の実装を利用する
続いて、Swift側で定義した処理(ネイティブ側の処理)をC#から利用する方法について見ていきます。
まずはコード全文を載せます。
using System.Runtime.InteropServices; using TMPro; using UnityEngine; public class SwiftPluginTest : MonoBehaviour { #if UNITY_EDITOR_OSX private const string DLL_NAME = "libSwiftPlugin"; #elif UNITY_IOS private const string DLL_NAME = "__Internal"; #endif #if UNITY_EDITOR_OSX || UNITY_IOS [DllImport(DLL_NAME, CallingConvention = CallingConvention.Cdecl)] internal static extern int calc(int a, int b); [SerializeField] private TMP_Text _text; private void Start() { int result = calc(10, 20); Debug.Log(result); _text.text = result.ToString(); } #endif }
ネイティブプラグインを利用する場合は DllImport 属性を利用し、外部で関数が定義されていることを伝えます。また、Swift側で @_cdelc 呼び出し規約を指定しているので、C#側も CallingConvention.Cdecl を指定します。
詳細についてはUnityのネイティブプラグインの作り方などを参照してください。
ここでの注意点は、macOSの場合はプラグイン名(ファイル名)を指定する必要がありますが、iOSの場合は __Internal を指定する必要がある点です。
関数については宣言だけを行っておけば、実行時はライブラリの関数を参照するようにコンパイルされます。
利用については通常のC#のメソッドと同様に呼び出すだけでOKです。
int result = calc(10, 20);
実行すると、確かにライブラリ側の処理が実行されていることが分かります。(ちゃんと 30 とログが表示されている)
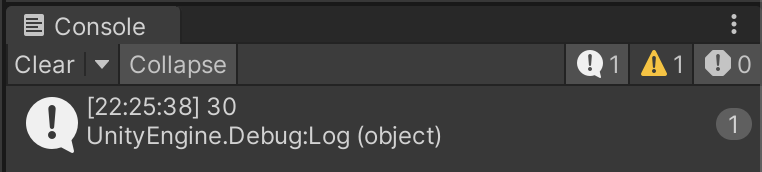
これで、Swift側で実装した内容をC#から(Unityから)呼び出すことができました。iOS用のライブラリも追加してあるので実機にビルドしてもちゃんと動作します。
Swiftのクラスを利用する
さて、関数を単体で定義してそれを呼び出すだけでは、ほとんどの場合そもそもC#だけでも行える可能性が高いです。実プロジェクトでは様々なライブラリの依存や、クラスの利用などが想定されます。
次では、Swift側で定義したクラスをC#側から利用する方法について見ていきます。
まずは以下のようにクラスを定義します。
public class NativeUtility { public func add(a: Int32, b: Int32) -> Int32 { a + b } public func sub(a: Int32, b: Int32) -> Int32 { a - b } }
ただ、C#側からは直接、Swiftのクラス情報にアクセスすることができません。そのため、以下のように、クラス情報を扱うための関数を別途定義します。
@_cdecl("create_instance") public func create_instance() -> UnsafeMutableRawPointer { let utility: NativeUtility = NativeUtility() return Unmanaged.passRetained(utility).toOpaque() } @_cdecl("use_utility_add") public func use_utility_add(_ pointer: UnsafeMutableRawPointer, _ a: Int32, _ b: Int32) -> Int32 { let instance: NativeUtility = Unmanaged<NativeUtility>.fromOpaque(pointer).takeUnretainedValue() return instance.add(a: a, b: b) } @_cdecl("use_utility_sub") public func use_utility_sub(_ pointer: UnsafeMutableRawPointer, _ a: Int32, _ b: Int32) -> Int32 { let instance: NativeUtility = Unmanaged<NativeUtility>.fromOpaque(pointer).takeUnretainedValue() return instance.sub(a: a, b: b) }
※ 今回はサンプルのため、インスタンスの解放などの処理は書いていませんが、実際のプロジェクトで利用する場合は、インスタンスの破棄などの処理も必要になるでしょう。
なにをしているかざっくり解説すると、 @_cdecl 属性によって extern C のように外部に関数名を公開します。そしてインスタンスの生成とそれを利用する関数を定義しています。
C#から関数へはアクセスできるため、Swift側のクラス情報を「ポインタ」という形でリレーすることで処理を実行するようにしている、というわけです。
なのでこれを利用する場合は create_instance 関数でインスタンスのポインタを生成し、 use_utility_*** でインスタンスを渡して実行している、というわけですね。( use_utility_*** となっていますが、これは決められた名前ではなく任意の名前を付けることができます。念のため)
ポインタを利用する
関数の内部がややごちゃごちゃしていますが、これはSwift側の参照カウンタなどの処理を活用するための処理です。ひとつずつ見ていきましょう。
まずはインスタンスの生成から。
@_cdecl("create_instance") public func create_instance() -> UnsafeMutableRawPointer { let utility: NativeUtility = NativeUtility() return Unmanaged.passRetained(utility).toOpaque() }
インスタンス生成関数の戻り値は UnsafeMutableRawPointer です。
※ Mutableなので UnsafeRawPointer に変換して利用するほうがより安全かもしれませんが、さらに処理が増えてしまうのでシンプルさ重視で書いています。
まずは普通にインスタンスを生成し、それを Unmanage.passRetained().toOpaque() で UnsafeMutableRawPointer に変換して返しています。
次に、実際にクラス(インスタンス)を利用する関数です。
@_cdecl("use_utility_add") public func use_utility_add(_ pointer: UnsafeMutableRawPointer, _ a: Int32, _ b: Int32) -> Int32 { let instance: NativeUtility = Unmanaged<NativeUtility>.fromOpaque(pointer).takeUnretainedValue() return instance.add(a: a, b: b) }
第一引数に、先ほど生成したインスタンスをポインタとして渡していますね。ポインタを経由していると書いたのはこれが理由です。そして関数内でポインタから元のクラスのインスタンスに変換した上で、利用したいメソッドを実行しているわけです。
Unmanaged<CLASS_NAME>.fromOpaque(<POINTER>).takeUnretainedValue() によってインスタンスを得ています。
ちなみに takeUnretainedValue は、インスタンスを得る際に参照カウンタを増加させずに取得する方法です。いわゆるweak pointer的な感じでしょうか。(あまりSwiftに詳しくないので想像ですが)
こうすることで、参照カウンタを増やさずに機能だけを利用することができます。逆に、参照カウンタを得たい場合は takeRetainedValue() を使います。
インスタンスが取得できれば、あとは利用したいメソッドを実行するだけですね。
Swift側のクラスを利用する方法で、Swift側の準備は以上です。
ちなみに込み入ったことをやろうとするとラッパーが増えていくことになりますが、ネイティブな機能を呼び出したいケースというのは局所的であることが多いと思います。もし複雑なことをやりたい場合は、Swift側でさらにラッパークラスを使って、そのクラスの中に処理を詰め込み、C#からは処理の開始などだけを依頼するような形がいいと思います。
C#から呼び出す
Swift側の準備が終わったので、最後にC#からどう利用するかを見ていきましょう。といっても、基本的な作法は前述のものと変わりません。違いは IntPtr を使う点くらいです。
以下は、新しく追記した部分の抜粋です。
[DllImport(DLL_NAME, CallingConvention = CallingConvention.Cdecl)] internal static extern IntPtr create_instance(); [DllImport(DLL_NAME, CallingConvention = CallingConvention.Cdecl)] internal static extern int use_utility_add(IntPtr instance, int a, int b); [DllImport(DLL_NAME, CallingConvention = CallingConvention.Cdecl)] internal static extern int use_utility_sub(IntPtr instance, int a, int b); private void Start() { // 中略 { IntPtr instance = create_instance(); int result2 = use_utility_add(instance, 25, 32); Debug.Log(result2); _text2.text = result2.ToString(); } }
最初のときと同じように DllImport 属性を付与して関数を宣言しています。そして利用する部分は、まずインスタンスを生成し、それをポインタ( IntPtr )として受け取り、それを使って対象のメソッドを呼び出す、という処理になっています。

しっかりと計算されているのが分かります。
以上でSwiftを利用する方法の解説は終わりです。
以下はもう少し発展した使い方などを書いていきます。
Swift側の文字列(String)を扱う
さて、上のサンプルは Int32 型、つまり整数のみを扱っていたのでやり取りはそこまで複雑ではありませんでした。整数などはシンプルなビット配列なのでネイティブ側とのやり取りもシンプルになります。
しかし、文字列など少し込み入った情報をやり取りする場合はそうもいきません。以下は、Swift側で生成した文字列をC#側で扱う方法について見ていきましょう。
Swift側の定義
まずはSwift側での定義を見てみます。
import Foundation // strdupを使うのにこれが必要 public class NativeUtility { // 中略 public func version() -> String { "1.0.0" } } @_cdecl("use_utility_version") public func use_utility_version(_ pointer: UnsafeMutableRawPointer) -> UnsafeMutablePointer<CChar> { let instance: NativeUtility = Unmanaged<NativeUtility>.fromOpaque(pointer).takeUnretainedValue() let version = instance.version() return strdup(version) }
Swift側の文字列を UnsafeMutablePointer<CChar> 型に変換しているのがポイントです。これまたポインタ経由でやり取りするわけですね。ポインタ万能。
ちなみに文字列をポインタに変換するには strdup() 関数を使います。これを利用するためには import Foundation とする必要がある点に注意です。
C#で文字列を受け取る
ではC#でどう文字列を受け取るかを見ていきましょう。
[DllImport(DLL_NAME, CallingConvention = CallingConvention.Cdecl)] internal static extern IntPtr use_utility_version(IntPtr instance); private void Start() { // 中略 IntPtr instance = create_instance(); int result2 = use_utility_add(instance, 25, 32); Debug.Log(result2); _text2.text = result2.ToString(); IntPtr strPtr = use_utility_version(instance); string result3 = Marshal.PtrToStringAnsi(strPtr); Debug.Log(result3); _text3.text = result3; Marshal.FreeHGlobal(strPtr); }
例に漏れず関数呼び出しの宣言を追加します。戻り値が IntPtr になっている点に注目です。文字列そのものをやり取りするのではなく、いったんポインタを経由するのはインスタンスのやり取りと同じですね。文字列のインスタンスをやり取りする、と考えると分かりやすいでしょう。
そして取得した文字列ポインタをC#の文字列に変換します。変換するには Marshal.PtrToStringAnsi(<POINTER>) を使います。戻り値はC#の string なのであとはそのまま利用するだけですね。
注意点として、文字列を使い終わったら Marshal.FreeHGlobal(<POINTER>) を実行して解放してやる必要があります。
C#から文字列を送る
ではC#から文字列を送る場合はどうでしょうか?
まずはSwiftの定義から見ていきましょう。
public class NativeUtility { // 中略 public func stringDecoration(str: String) -> String { "Decorated[\(str)]" } } @_cdecl("use_utility_decorate") public func use_utility_decorate(_ pointer: UnsafeMutableRawPointer, _ text: UnsafePointer<CChar>) -> UnsafeMutablePointer<CChar> { let instance: NativeUtility = Unmanaged<NativeUtility>.fromOpaque(pointer).takeUnretainedValue() let string = String(cString: text) let result = instance.stringDecoration(str: string) return strdup(result) }
文字列を返す場合は UnsafeMutablePointer<CChar> 型でしたが、受け取る場合は UnsafePointer<CChar> 型で受け取ります。
Swiftの String 型への変換は String のコンストラクタにポインタを渡すだけですね。あとは普通に String として利用するだけです。
今回のサンプルでは加工した文字列を返しているので、前述の、C#へ文字列を返す方法をそのまま利用しています。
C#とSwift間で整数(プリミティブ)、文字列、インスタンスのやり取りの方法の解説は以上です。
最後に、ネイティブ側からC#のコードを呼び出すコールバックについて解説します。少しだけ準備が増えます。
ネイティブ側からC#の関数を呼ぶコールバックの実装
今自分が実装を試みているのが、Swift側で非同期処理があるパターンです。そのため、処理が終わってからC#側の処理を呼び出さないとなりません。当然、C#側の async / await は利用できないのでコールバックという形で結果を受け取ります。
まず、SwiftとC#双方でコールバック(関数ポインタ)の型を宣言する必要があります。順番に見ていきましょう。
Swift側でコールバックの型を宣言
まずはSwift側から見てみましょう。
public typealias completion_callback = @convention(c) (Int32) -> Void @_cdecl("async_test") public func async_test(_ completion: completion_callback) -> Void { DispatchQueue.global().async { completion(35) } }
今回はネイティブ側から整数を送るだけのものを宣言しています。そしてそれを受け取る関数を定義し、処理が終わったのちに関数として呼び出しています。
C#側でもコールバックの型を宣言
次にC#側を見てみましょう。
[UnmanagedFunctionPointer(CallingConvention.Cdecl)] private delegate void CompletionCallback(int result); [DllImport(kLibName, CallingConvention = CallingConvention.Cdecl)] private static extern void async_test(IntPtr callback); private CompletionCallback _completionCallback; private GCHandle _gcHandle; private void Callback(int result) { Debug.Log(result); // コールバックを渡す関数を実行する前に `GCHandle` を取得しているので、それを解放する。 _gcHandle.Free(); } private void CallWithCallback() { _completionCallback = Callback; IntPtr pointer = Marshal.GetFunctionPointerForDelegate(_completionCallback); _gcHandle = GCHandle.Alloc(_completionCallback); async_test(pointer); }
C#側の準備はちょっと多めになります。まず、コールバックの型を宣言しています。宣言の際に UnmanagedFunctionPointer 属性を付与しています。
そして delegate を保持する変数を準備し、さらにガベージコレクションされないように GCHandle の変数も用意します。あとはコールバックそのものを定義していますね。
こうして準備したものを用いてコールバックを渡して実行します。
delegate を IntPtr に変換してから渡しているのがポイントです。変換には Marshal.GetFunctionPointerForDelegate(<DELEGATE>) を使います。
また GCHandle を取得したのちにネイティブ側の関数を呼び出しています。
最後に、コールバックが呼ばれたら確保したハンドルを解放して終わりです。
文字列やクラスのインスタンスと同様、ネイティブ側とのこうしたやり取りには基本的にポインタを利用する、と覚えておくといいでしょう。
GCHandleが必要な理由
なぜこの GCHandle.Alloc を行っているのでしょうか。これはマネージドコード特有の問題です。C#は定期的にガベージコレクタによってメモリの解放が行われます。この際、場合によってはメモリの最適化のためにポインタの位置が変更される可能性があります。もし非同期処理の実行後にコールバック呼び出しのために、変更前のアドレスにアクセスしてしまうと当然、クラッシュの要因となってしまいます。
これを避けるために GCHandle を利用しているというわけです。
最後に、パッケージ間の依存について話をして今回の記事を終わりにしたいと思います。
依存のあるパッケージについて
今回のサンプルではひとつのパッケージのみを作成しました。しかし、パッケージには依存関係を定義することができます。
例として新しく SwiftPluginWrapper というパッケージを作成し、依存関係を作ってみます。
コマンドで生成された Package.swift の Package に dependencies を追加しリソースの場所を指定します。そして targets にも dependencies を追加してパッケージ名を指定します。
// swift-tools-version: 5.9 // The swift-tools-version declares the minimum version of Swift required to build this package. import PackageDescription let package = Package( name: "SwiftPluginWrapper", products: [ // Products define the executables and libraries a package produces, making them visible to other packages. .library( name: "SwiftPluginWrapper", type: .dynamic, targets: ["SwiftPluginWrapper"]), ], dependencies: [ .package(path: "../SwiftPlugin"), // GitHub上のパッケージなども指定することができる // .package(url: "https://github.com/<USER_NAME>/<REPOSITORY_NAME>.git", branch: "main"), ], targets: [ // Targets are the basic building blocks of a package, defining a module or a test suite. // Targets can depend on other targets in this package and products from dependencies. .target( name: "SwiftPluginWrapper", // リソースの場所だけでなく、依存関係として `dependencies` を追加する。追加するのはパッケージ名 dependencies: ["SwiftPlugin"]), .testTarget( name: "SwiftPluginWrapperTests", dependencies: ["SwiftPluginWrapper"]), ] )
するとこのパッケージの依存関係が定義でき、依存先のパッケージの内容を利用することができるようになります。
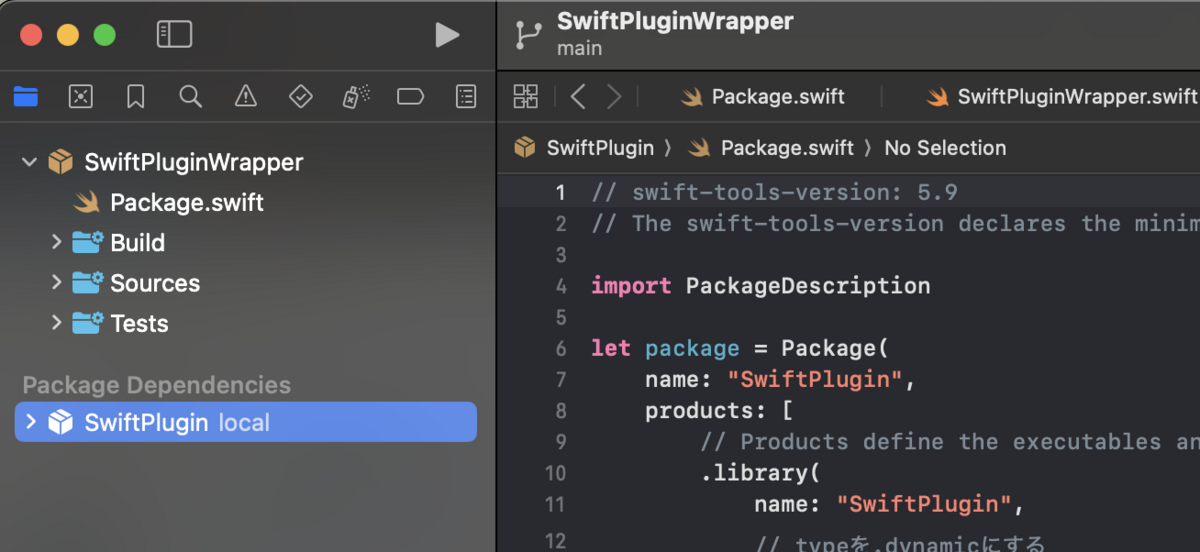
ラッパーパッケージ側を開くと、 Package Dependencies として SwiftPlugin が認識されているのが分かります。
実際に、指定したパッケージを利用するようにしてコードを書いてみます。
import SwiftPlugin @_cdecl("add") public func add(_ a: Int32, _ b: Int32) -> Int32 { let utility: NativeUtility = NativeUtility() let result: Int32 = utility.add(a: a, b: b) return result }
add 関数の中で SwiftPlugin 側の NativeUtility クラスをインスタンス化しているのが分かります。
これをビルドしてUnity側で利用してみましょう。
依存関係があるパッケージをビルドすると、依存先(GitHub上のパッケージなど)も自動的に追加されビルド対象となります。
ちなみにローカルの場合はふたつのパッケージがそれぞれビルドされました。GitHub上のものを指定したときはひとつのライブラリになったので、依存のさせた方によって挙動が異なるかもしれません。適宜、生成されたライブラリをインポートするようにしてください。
上記の設定でビルドした結果が以下です。ふたつのパッケージ(libSwiftPlugin と libSwiftPluginWrapper)の .dylib ファイルができているのが確認できます。
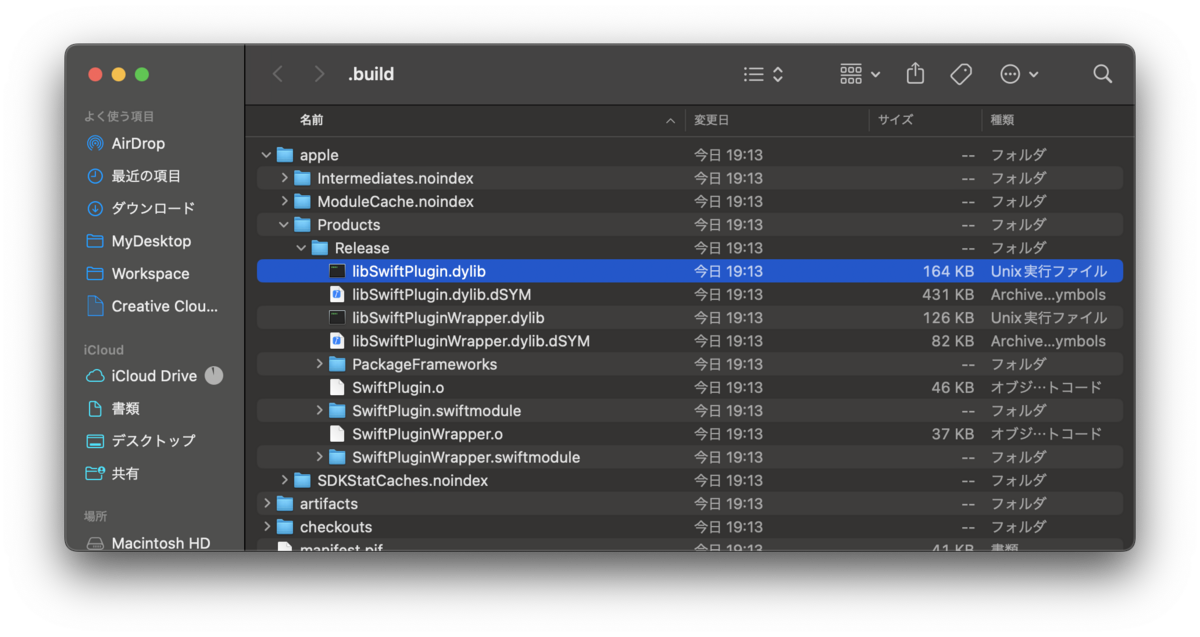
iOS向けも同様に SwiftPlugin と SwiftPluginWrapper の .framework が生成されています。

これの使い方は前述の通りです。 .dylib および .framework をUnityにインポートし、 DllImport 属性を付与した関数を定義すれば利用できます。
以下は実行した結果です。

ラッパーライブラリ側から、 libSwiftPlugin 内のコードも正常に呼び出せていることが確認できます。
注意点メモ
Unityはリロードが必要
Unityは、ライブラリを一度ロードするとリロードしてくれません。そのため、今回のように徐々に機能を作っていく場合、新しくビルドしたライブラリを入れ直しても処理が更新されません。反映させたい場合はUnityを再起動してください。
パッケージの依存が解決できない
GitHub上のパッケージを指定した場合、基本的にはなにもしなくても利用可能になりますが、GitHubのリポジトリ名とパッケージ名が一致していない場合、パッケージの依存関係が解決できずにエラーになってしまう現象がありました。
その場合は以下のように dependencies を設定すれば解決できます。
// GitHub上のパッケージを指定 dependencies: [ .package(url: "https://github.com/ggerganov/llama.cpp.git", branch: "master"), ], // dependenciesには `.product` を利用して名前とパッケージ名を指定 .target( name: "llamacpp-wrapper", dependencies: [ .product( name: "llama", package: "llama.cpp") ]),
応用編
SwiftではなくC++になってしまいますが、NDIというネットワークで映像を配信できるフレームワークのC++実装を、Unityで扱えるようにした記事を以前に書きました。実際に存在しているフレームワーク・ライブラリをUnityで扱えるようにしたものなので、今回のサンプルではなく実際に利用する際の実装の仕方の参考になると思うので、興味があったらぜひ読んでみてください。
まとめ
Swiftパッケージはかなり簡単にライブラリ化することができます。とはいえ、今回のようなシンプルな構成ではないとビルド時にエラーなどが発生するかもしれません。しかし、基本となる部分をおさえておけば、問題が起きたときの切り分けも簡単になるでしょう。
最近ではApple Vision Proが発売され、iOSのみならずvisionOSも登場しました。今後、Swiftを利用してvisionOS向けのライブラリなども作ることになっていくと思います。特にApple Vision Pro開発はUnityではかゆいところに手が届かないことも多々あります。
そのときはSwift側で機能を実装して、それをUnity(C#)から呼び出す、という構成を取る必要が出てくることもあり得るでしょう。そんなときに参考にしてみてください。
QuestのパススルーとVR Room機能を利用してMixed Realityを実現する

概要
Questのパススルーの機能が拡充され、MRアプリとして色々と利用できるようになっているので、その機能を利用するためのメモを書いていきます。具体的には、以下の動画のように、自分で設定したオブジェクト(机や椅子、本棚など)を制御して「自分の部屋をVR空間にしていく」ための方法のメモです。
QuestのVRルームでオブジェクトを個別に認識してMRとして利用してみた。面白いもの作れそう#Quest2 #QuestPro #VR #MR #AR #Unity #madewithunity pic.twitter.com/4DNevIMQzd
— edom18@XR / MESON CTO (@edo_m18) 2022年12月29日
ちなみにこの機能を実装するにあたって、Metaが提供している The World Beyond を参考にしました。さらにうれしいことにそのUnityプロジェクトはGitHubに公開されているので興味がある方はぜひ見てみてください。
動作サンプル
また、今回のサンプルの機能部分(パススルーの有効化など)についてはGitHubにアップしてあるので、実際に動くものを見たい場合はこちらをダウンロードして確認ください。
パススルーの設定
まず、冒頭の動画のようなコンテンツを作成する場合、ビデオパススルーを有効化する必要があります。いくつか手順が必要で、特にエラーなども出ないので注意が必要です。
ここでは必要な要素のみを取り上げますが、以前に、より詳細な記事を書いているのでそちらも合わせて参照ください。
※ なお、以下の記事を書いたときはまだ実験的機能だったために必要だった処理もありましたが、現在はいくつかは行わなくても大丈夫になっているようです。
パススルーを有効化する
パススルーを有効化するには以下の手順を実行してください。
Player Settings にて以下を設定します。
- Scripting Backendを
IL2CPPにする - Target Architectureを
ARM64にする
OVRCameraRig Prefabにあるコンポーネントの OVRManager の以下の項目を設定します。
Anchor SupportをEnabledにするPassthrough Capability EnabledのチェックをオンにするEnable Passthroughのチェックをオンにする
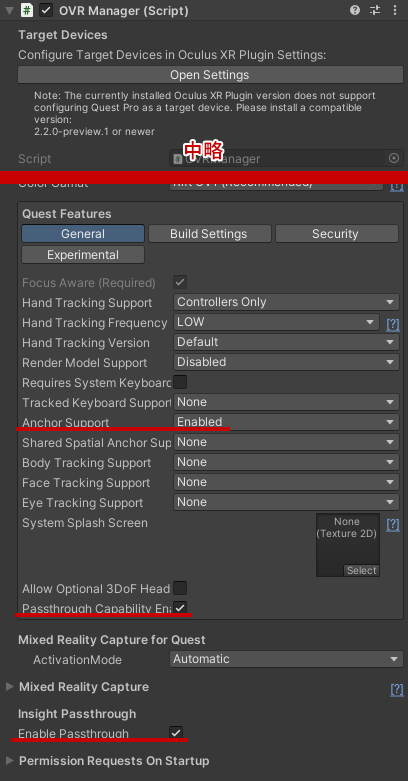
※ 画像内の Quest Features は厳密には OVRProjectConfig という ScriptableObject でできたアセットの設定を OVRManager が分かりやすく表示しています。そのため、本来の設定はそのアセットに保存されます。
OVRCameraRigオブジェクトにOVRPassthroughLayerコンポーネントを追加するOVRPassthroughLayerのPlacementをUnderlayに変更する
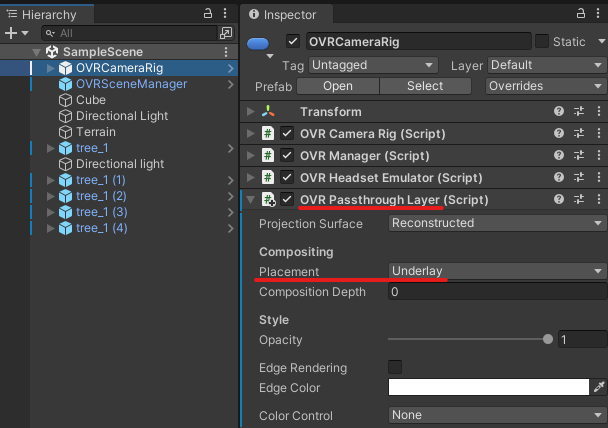
上記までを設定することでビデオパススルーが有効化され、利用できるようになります。
各リアルオブジェクトを利用する
次に、リアルオブジェクト(VR Room機能で設定した壁や窓など)をシーン内に表現するための設定を行います。
OVRSceneManager をシーンに配置する
Meta XR Utilities に含まれている OVRSceneManager プレファブをシーン内に配置します。設置したら所定のパラメータに適切にオブジェクトを設定します。(詳細は後述します)
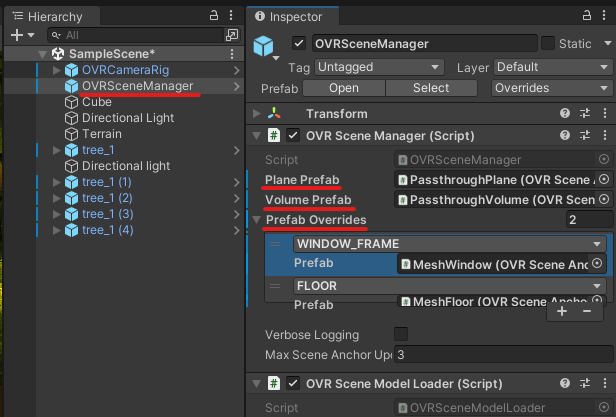
OVRSceneModelLoaderをアタッチする
OVRSceneManager をアタッチしたオブジェクトに、追加で OVRSceneModelLoader をアタッチします。
リアルオブジェクトを表す OVRSceneAnchor
OVRSceneManager のインスペクタに設定するオブジェクト(Prefab)は OVRSceneAnchor コンポーネントを持っている必要があります。このコンポーネントがリアルオブジェクトを表す単位となります。スクリプトのコメントを引用すると以下のように説明されています。
A scene anchor is a type of anchor that is provided by the system. It represents an item in the physical environment, such as a plane or volume. Scene anchors are created by the OVRSceneManager.
シーンアンカーはシステムから提供されるアンカーのタイプです。物理環境の平面やボリュームなどのひとつのアイテムを表現します。シーンアンカーは
OVRSceneManagerによって生成されます。
上記画像の意味をひとつひとつ見ていきましょう。
平面用Prefab Plane Prefab
ひとつ目の項目は Plane Prefab です。これはリアルオブジェクトのうち、平面として表されるオブジェクト用に利用されます。例えば机や椅子などの平面です。また壁や天井なども平面で定義されるため、このPrefabが利用されます。( Instantiate される)
ボリューム用Prefab Volume Prefab
もうひとつの Volume Prefab は、ボリューム、つまり体積を持つ単位で利用されるPrefabです。例えばVR Room機能で Other で設定され、VR Roomのプレビューで立方体で表されるオブジェクトがこれに該当します。
それぞれのPrefabはオーバーライドできる
最後の Prefab Overrides は、壁や天井など、特定のリアルオブジェクトを専用のPrefabでオーバーライドするためのものです。例えば、床はこのPrefabを利用して特殊なテクスチャが貼ってあるようにする、などの使い方ができます。
Prefabの構成
OVRSceneManager に設定するPrefabの構成は以下の通りです。
Plane Prefabの構成
Plane Prefab に設定しているPrefabは以下の構成になります。トップオブジェクトに OVRSceneAnchor を付け、その下にMeshを配置しているだけですね。ただ、Meshに設定するマテリアルは Transparent のQueueより少し早めに描画しておく必要があるようです。

Volume Prefabの構成
Volume Prefab に設定しているのは以下の構成になります。 Plane Prefab と同様、トップオブジェクトに OVRSceneAnchor を付け、その下に Parent > Mesh という階層でオブジェクトを配置しています。 Parent はコンポーネントがなにもないオブジェクトでおそらくPivot的に使われるものと思われます。そして最下層のMeshは Plane Prefab と異なり、Cube型のオブジェクトを配置しています。


Prefab Overridesに設定するPrefabの構成
最後に、オーバーライドするPrefabの構成についてです。こちらは以下のような構成になっていました。上記構成と共通の設定として、 OVRSceneAnchor を追加し、逆に上記の構成と異なる点としては OVRScenePlaneMeshFilter コンポーネントを追加しています。Meshに設定しているマテリアルは上記のものと同様です。
マテリアルについて
Prefabに設定しているマテリアルですが、Queue以外に色を調整する必要があります。具体的には、
- 色を黒にする
- アルファを0にする(= 完全透明にする)
理由としては、色は加算されるため白にすると真っ白になってしまいます。そしてアルファの値はパススルー映像の透過させるために0にしておく必要があります。
壁を透過させてVRのように見せる
冒頭の動画のように、パススルーで見ているところを透過してVRのように見せる方法はとてもシンプルです。生成された壁のオブジェクトは Plane Prefab に登録された汎用なものか、あるいはオーバーライドされたPrefabで構成されています。Planeの名前の通りただの平面オブジェクトなのでそれを「非表示」にしてしまえば遮蔽するものがなくなり、その奥に広がっているVR空間が顔を出す、というわけです。
また、オーバーライドできることを利用して、例えば壁には特殊なコンポーネントを付与しておき、ポイントされたら円形の形にくり抜いて奥を見せる、などの細かな制御を行うことができるでしょう。
まとめ
実際に触ってみて思ったのは、大部分のところをMeta XR Utility側でやってくれるので本当に必要なところだけを実装するだけでOKでした。大まかな仕組みは理解したのでこれを利用してコンテンツをひとつ作ってみようと思います。
実際のコンテンツの場合は「どのドア」とか「どの窓」など複数登録できるオブジェクトをどうやって有効利用するかを決めないとならないのでもうひと手間かかるかなとは思っています。とはいえ、大枠として「ドアがここ」などが分かるのはMRコンテンツを作成する上でかなり大きな意味を持つと思います。ぜひみなさんも面白いアイデアが思いついたら実装してみてください。