llama.cppをUnityで扱う

去年(2023年)の3月頃にChatGPTのAPIが公開されてから、AI熱が高まり最近では様々な生成AIが毎日のようにニュースになっています。
MESONでもAIには積極的に取り組んでいて、自分もとてもAIに興味があります。
生成AIでは特に大規模言語モデル(LLM)に興味があって、人生の中で一番ワクワクしているときかもしれません。
このLLM、うまく使えばかなり色々なことが実現できます。特に、ローカルで動くLLMが当たり前になってくると本当にSFの世界のような体験が作れるのでは、と期待しています。
そんなわけなので、ローカルで、特にスマホでLLMを動かすことにとても興味があり、かつ自分はUnityエンジニアなのでLLMをUnityアプリに組み込みたいなと考えていました。
そしてllama.cppという素晴らしいプロジェクトがあります。これは、Meta社が公開しているLlamaというオープンソースのLLMをC++で実装し、様々な環境で動かせるようにしてくれているリポジトリです。
その中でllamacpp.swiftという、iOS向けのプロジェクトがサンプルにあり、iOS実機で試すことができるようになっています。
幸いなことにこれはSwiftパッケージの形で提供されているため、これをビルドしてUnityに組み込む、というのが今回の記事の主題です。
実際に動かしてみたのが以下の動画です。
llamacppをUnityで動かすやつ。llamacpp.swiftにデフォルト設定されてるモデルだと、ネイティブアプリと同じ速度感だったので、やはりモデルの問題だった。ので、llamacppがUnityで動く環境は手に入れられたぞ#LLAMA #llamacpp #Unity #madewithunity pic.twitter.com/HVCNwwvGUV
— edom18@XR / MESON CTO (@edo_m18) 2024年2月26日
この組み込みを行う上で少しハマったのでそれを備忘録として残しておきます。
今回実装したものはGitHubに上げてあるので全体を見たい人は参考にしてください。
▼ Unity
▼ Xcode(llamacpp-wrapper)
※ モデルは小さなものでも1GB近くあったりするのでリポジトリには含まれていません。そのため、ご自身でダウンロードして Assets/StreamingAssets/models 内に配置してください。
今回利用したモデルはこちらのモデル(tinyllama-1.1b-1t-openorca.Q4_0.gguf)です。
Unityに組み込む準備
Unityに組み込むにあたり、Swiftパッケージをそのまま持って行くことはできません。また、開発の効率を考えるとUnity Editor上でも動かせる必要があります。ということで、macOS向けとiOS向けにパッケージをビルドし、双方で扱えるようにすることを目標とします。
iOS / macOS向けにビルドする
Swiftパッケージを両プラットフォーム向けにビルドするところから始めましょう。といっても、ビルドに関する記事は前回書いたので、ビルドの仕方そのものは前回の記事を参考にしてください。ここではllama.cppのビルドのみに焦点を絞って書きます。
llama.cppをラップするSwiftパッケージを作成する
llama.cpp自体はSwiftパッケージとして利用できる形になっていますが、本体はC++で実装されています。そのため、llama.cppのパッケージをそのままビルドしてもUnity側で扱える形になっていません。そこで、llama.cppをラップするパッケージを作成し、そのパッケージの依存先としてllama.cppを設定する、という形で実装を行います。
つまりこのパッケージの目的はllama.cppの機能をC#から利用できるようにインターフェースの役割を担います。
前回の記事でも、自作のSwiftパッケージを外部のパッケージに依存させる方法を書いているので詳細はそちらを参照ください。
まずはSwiftパッケージを新規作成(初期化)し、llama.cppを依存関係に追加します。
Swiftパッケージの作成は以下のようにコマンドを実行してください。
$ mkdir llama-wrapper $ cd llama-wrapper $ swift package init --type library --name llama-wrapper
上記コマンドを実行するとパッケージに必要なファイルなどが自動生成されます。その中でパッケージの情報を示す Package.swift があるので、必要な設定をしていきます。
具体的には以下を追加・修正します。
dependenciesにllama.cppを追加する- GitHub上の名前と一致しないので名前の指定
- ライブラリの
typeを.dynamicにして共有ライブラリとする - 対応Platformの指定を追加
最終的に以下のようになります。(必要な部分だけ抜粋)
let package = Package( name: "llamacpp-wrapper", platforms: [ .macOS(.v13), .iOS(.v16), .watchOS(.v4), .tvOS(.v14) ], products: [ .library( name: "llamacpp-wrapper", type: .dynamic, targets: ["llamacpp-wrapper"]), ], dependencies: [ .package(url: "https://github.com/ggerganov/llama.cpp.git", branch: "master"), ], targets: [ .target( name: "llamacpp-wrapper", dependencies: [ .product( name: "llama", package: "llama.cpp") ]), // 後略 }
Platformにはビルドの際に、対応バージョンなどによってエラーが発生するのでその下限に適合するように指定しています。
まずはビルドしてみる
現時点でビルドが通る状態になっているはずです。特に機能は実装していませんが、以下のコマンドを実行してそれぞれのプラットフォーム向けにビルドできるか確認しておきましょう。
▼ macOS向け
$ swift build -c release --arch arm64 --arch x86_64
macOS向けのビルドは自動的に .build フォルダにビルドされるので、もしFinderなどで見ている場合に不可視ファイルの可能性があるのでターミナルなどから開いてください。
▼ iOS向け
$ xcodebuild -scheme llama-wrapper -configuration Release -sdk iphoneos -destination generic/platform=iOS -derivedDataPath ./Build/Framework build
iOSの場合はビルド先フォルダを指定しているのでそのフォルダを開きます。
※ 前回のビルドの解説のところでも書いたのですが、生成直後のものをビルドしてもTestターゲット向けのビルドでコケるので、今回はひとまずコメントアウトして回避しています。
// .testTarget( // name: "llamacpp-wrapperTests", // dependencies: ["llamacpp-wrapper"]),
これでパッケージ作成の準備が整いました。以下から実際に実装をしていきます。
ラッパーを実装する
前段まででUnityに組み込む準備ができました。続いてllama.cppの機能をC#から呼び出すための処理などを追加していきます。
llama.cppの実装を呼び出す機能の実装
llamacpp.swift に含まれている実装をそのまま移植します。具体的には LibLlama.swift をコピーします。この実装は名前から推測できる通り、C++側の実装を呼び出し実際に推論などを行う実装が含まれています。
以下のように追加しました。
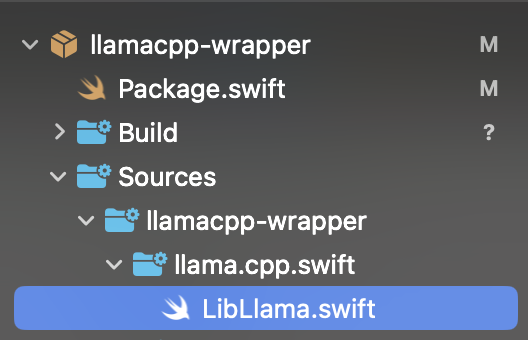
今回新規で追加するのは、この LibLlama.swift に実装されている LlamaContext クラスの処理をC#から呼び出せるようにするものです。
今回の実装は、 LibLlama.swift と同様にllama.cppに含まれていた LlamaState.swift の実装を参考にしました。
まずは今回実装したコード全文を載せます。その後、個別に解説します。
import llama import Foundation public typealias completion_callback = @convention(c) (UnsafeMutablePointer<CChar>) -> Void public class LlamaWrapper { let NS_PER_S = 1_000_000_000.0 var llamaContext: LlamaContext? var message: String = "" init() { } init(llamaContext: LlamaContext) { self.llamaContext = llamaContext } public func complete(text: String, completion: completion_callback) async -> Void { self.message = "" let t_start = DispatchTime.now().uptimeNanoseconds await self.llamaContext?.completion_init(text: text) let t_heat_end = DispatchTime.now().uptimeNanoseconds let t_heat = Double(t_heat_end - t_start) / NS_PER_S self.message += "\(text)" guard let llamaContext = self.llamaContext else { let faileMessage = strdup("Failed to create text.") completion(faileMessage!) return } while await llamaContext.n_cur < llamaContext.n_len { let result = await llamaContext.completion_loop() self.message += "\(result)" print(result) } let t_end = DispatchTime.now().uptimeNanoseconds let t_generation = Double(t_end - t_heat_end) / NS_PER_S let tokens_per_second = Double(await llamaContext.n_len) / t_generation await llamaContext.clear() self.message += """ \n Done Heat up took \(t_heat)s Generated \(tokens_per_second) t/s\n """ let messagePtr = strdup(self.message) completion(messagePtr!) } } @_cdecl("create_instance") public func create_instance(_ pathPtr: UnsafePointer<CChar>) -> UnsafeMutableRawPointer { let path = String(cString: pathPtr) do { let llamaContext: LlamaContext = try LlamaContext.create_context(path: path) let wrapper: LlamaWrapper = LlamaWrapper(llamaContext: llamaContext) return Unmanaged.passRetained(wrapper).toOpaque() } catch { let wrapper: LlamaWrapper = LlamaWrapper() return Unmanaged.passRetained(wrapper).toOpaque() } } @_cdecl("llama_complete") public func llama_complete(_ pointer: UnsafeMutableRawPointer, _ textPtr: UnsafePointer<CChar>, _ completion: completion_callback) -> Void { let llamaWrapper: LlamaWrapper = Unmanaged<LlamaWrapper>.fromOpaque(pointer).takeUnretainedValue() let text = String(cString: textPtr) Task { await llamaWrapper.complete(text: text, completion: completion) } }
ラッパークラスを実装
まずはラッパークラス( LlamaWrapper )を見ていきましょう。
ここの実装がまさに LlamaState.swift の実装を参考にしたものです。今回はあまり複雑なことはせず、C#から文字列を受け取り、それをもとにLLMで推論を行うだけのものになっています。
実際の推論については LlamaContext クラスで行うため、それを呼び出すラッパーとして実装しています。そのため、コンストラクタで LlamaContext のインスタンスを受け取って利用する形としています。
init(llamaContext: LlamaContext) { self.llamaContext = llamaContext }
生成過程については後述します。
続いて実際に推論する処理である complete メソッドを見ていきます。ここがまさに LlamaState.swift からの引用部分です。
public func complete(text: String, completion: completion_callback) async -> Void { self.message = "" let t_start = DispatchTime.now().uptimeNanoseconds await self.llamaContext?.completion_init(text: text) let t_heat_end = DispatchTime.now().uptimeNanoseconds let t_heat = Double(t_heat_end - t_start) / NS_PER_S self.message += "\(text)" guard let llamaContext = self.llamaContext else { let faileMessage = strdup("Failed to create text.") completion(faileMessage!) return } while await llamaContext.n_cur < llamaContext.n_len { let result = await llamaContext.completion_loop() self.message += "\(result)" print(result) } let t_end = DispatchTime.now().uptimeNanoseconds let t_generation = Double(t_end - t_heat_end) / NS_PER_S let tokens_per_second = Double(await llamaContext.n_len) / t_generation await llamaContext.clear() self.message += """ \n Done Heat up took \(t_heat)s Generated \(tokens_per_second) t/s\n """ let messagePtr = strdup(self.message) completion(messagePtr!) }
ここの処理が行っているのは各種時間計測と、 LlamaContext によって推論された文字列を結合していく処理になっています。
メインの処理はこの部分ですね。
while await llamaContext.n_cur < llamaContext.n_len { let result = await llamaContext.completion_loop() self.message += "\(result)" }
最終結果として利用する message プロパティに文字列を足し込んでいっているだけです。ちなみに非同期処理となるため、C#側へはコールバックを用いて結果を返すようにしています。
コールバックを使ってC#側で結果を受け取る
Swift側の非同期処理が挟まるため、結果を返すのにコールバックを用いています。コールバックの定義は以下のようになっています。
public typealias completion_callback = @convention(c) (UnsafeMutablePointer<CChar>) -> Void
上記で定義したコールバックのaliasを利用して関数の引数としてコールバックを受け取ります。
typealias の通り、 completion_callback を新しい型として利用できるように宣言しています。続く @convention(c) はC言語の関数呼び出し規約を適用するという意味です。
以下、ChatGPTに聞いて得られた回答です。
@convention(c): この属性は、関数ポインタがC言語の呼び出し規約を使用することを指定します。Swiftはデフォルトで自身の呼び出し規約を持っていますが、この属性を使用することで、C言語との相互運用が可能になります。特に、C言語のAPIと連携する場合や、C言語のライブラリをSwiftから使用する場合に重要です。
そしてこの型を利用して関数を受け取る関数を定義します。
public func llama_complete(_ pointer: UnsafeMutableRawPointer, _ textPtr: UnsafePointer<CChar>, _ completion: completion_callback) -> Void { }
こうすることで、実行完了後にC#側に結果を渡すことができます。
第一引数に UnsafeMutableRawPointer を受け取っていますが、これは LlamaWrapper クラスのインスタンスへのポインタです。C#から呼び出す際に指定しています。なぜこうする必要があるのかについては前回の記事を参考にしてください。
インスタンスの生成と取り回し
Swift側のクラスのインスタンスはポインタ経由でC#とやり取りするのが基本です。そのため、インスタンスの生成周りについて少しだけ解説しておきます。
インスタンスの生成処理は以下のようになっています。
@_cdecl("create_instance") public func create_instance(_ pathPtr: UnsafePointer<CChar>) -> UnsafeMutableRawPointer { let path = String(cString: pathPtr) do { let llamaContext: LlamaContext = try LlamaContext.create_context(path: path) let wrapper: LlamaWrapper = LlamaWrapper(llamaContext: llamaContext) return Unmanaged.passRetained(wrapper).toOpaque() } catch { let wrapper: LlamaWrapper = LlamaWrapper() return Unmanaged.passRetained(wrapper).toOpaque() } }
この関数がインターフェースとしてC#に公開されており、引数に文字列のポインタを受け取ります。これは推論を実行するモデルへのパスです。そのパスを渡して LlamaContext のインスタンスを生成します。生成時に失敗する可能性があるため try-catch していますが、本当であれば失敗時にエラーを通知する仕組みが必要ですが、今回は動かすことだけを目的にしているので細かい制御はしていません。もしエラーが発生したらコンテキストを持たない LlamaWrapper クラスを生成しているだけです。(なので当然、その場合は推論実行時にエラーになります)
無事、コンテキストが生成できたらそれを引数にして LlamaWrapper クラスのインスタンスを生成し、そのポインタを返します。前述の推論用関数の第一引数に渡ってくるのはこのインスタンスになります。
Swift側のクラスのインスタンス生成、それをC#で利用する方法についてのより詳細な内容は前回の記事を参照してください。
C#側の実装
次に、C#側でSwift側にコールバックを渡す方法について見ていきます。
まずは宣言を見てみましょう。
[UnmanagedFunctionPointer(CallingConvention.Cdecl)] private delegate void CompletionCallback(IntPtr resultPtr); [DllImport(kLibName, CallingConvention = CallingConvention.Cdecl)] private static extern void llama_complete(IntPtr instance, string text, IntPtr completion);
大事な点は2点。コールバックとして渡すための delegate の宣言時に UnmanagedFunctionPointer(CallingConvention.Cdecl) 属性を付与する点と、デリゲートそのものは IntPtr としてポインタで渡している点です。
実際に渡している処理を見てみましょう。
[MonoPInvokeCallback(typeof(CompletionCallback))] private static void StaticCallback(IntPtr resultPtr) { _instance.Callback(resultPtr); } private void Predict() { _completionCallback = StaticCallback; IntPtr completionPtr = Marshal.GetFunctionPointerForDelegate(_completionCallback); _gcHandle = GCHandle.Alloc(_completionCallback); llama_complete(_llamaInstance, _prompt.text, completionPtr); }
デリゲートとして渡すメソッドを定義しています。なお、IL2CPPの制約でインスタンスメソッドを渡すことができません。渡せるのはstaticメソッドのみなのでその点に注意です。
また定義時に [MonoPInvokeCallback(typeof(CompletionCallbac))] として属性を付与しています。P/Invokeとして利用できるようにするための処置ですね。
P/Invokeとは
P/InvokeはPlatform Invokeの略です。ドキュメントの説明を引用すると、
P/Invokeは、アンマネージドライブラリ内の構造体、コールバック、および関数をマネージドコードからアクセスできるようにするテクノロジです。P/Invoke APIのほとんどは
SystemとSystem.Runtime.InteropServicesの2つの名前空間に含まれます。これら2つの名前空間を使用すると、ネイティブコンポーネントと通信する方法を記述するツールを利用できます。
つまり、ネイティブ側とやり取りするための規約(API)ということですね。まさにネイティブ側から呼び出されるように設定するため、MonoPInvokeCallback 属性を付けているというわけです。
そして実際に呼び出す部分を見てみると、上記のstaticメソッドをデリゲート型の変数に設定し、それを Marshal.GetFunctionPointerForDelegate() を利用してポインタ( IntPtr )に変換しています。そしてそれを引数にしてSwift側の実装を呼び出す、という流れになっています。
Swift側の実装は前述の通りです。推論が終わったらその結果をコールバックで返してくれます。あとは受け取った結果をC#側で利用するだけですね。
実プロジェクトで使うには
今回紹介したのは、あくまでllama.cppをUnityで扱う点についてのみです。よく見るとstaticメソッドなため、コールバックした結果を、呼び出したインスタンス側で扱えません。
このあたりはllama.cppをどうやって使うのかの設計にも関わってきます。例えばllama.cppを呼び出すだけのシングルトン的なものを配置して、コールバックはそのインスタンスに登録してやり取りする、などです。ただその場合でも、受け取る側を特定するための準備が必要になるでしょう。
また、Swift側のインスタンスの破棄など実際に使うとなると様々な考慮が必要になります。なので、今回の実装を実プロジェクトでそのまま利用するのはむずかしいでしょう。ただ、利用する方法が分かっていればあとは設計次第なので、より実践的に使えるようにブラッシュアップしていく予定です。
最後に、実装を進める上でハマったポイントをメモしておきます。
ハマったポイント
以下は、今回の実装時にハマったポイントを記載しておきます。
llama.cppの実装を呼び出すとクラッシュする
最初、この実装を始める前に色々llama.cppでiOSネイティブアプリをビルドしたりして調査をしていました。そのときの master ブランチの状態ではUnityに持っていってもクラッシュしなかったのですが、最新版ではなぜかクラッシュするようになってしまいました。
Metal周りの初期化でエラーが出ているようなのですが、なにが原因かはまだ特定できていません。
ちなみに、クラッシュせずに実行できた状態のコミットハッシュは 5bf2b94dd4fb74378b78604023b31512fec55f8f でした。もしご自身で試す場合、同様のエラーが出た場合はこのコミットまで戻してから利用してみてください。
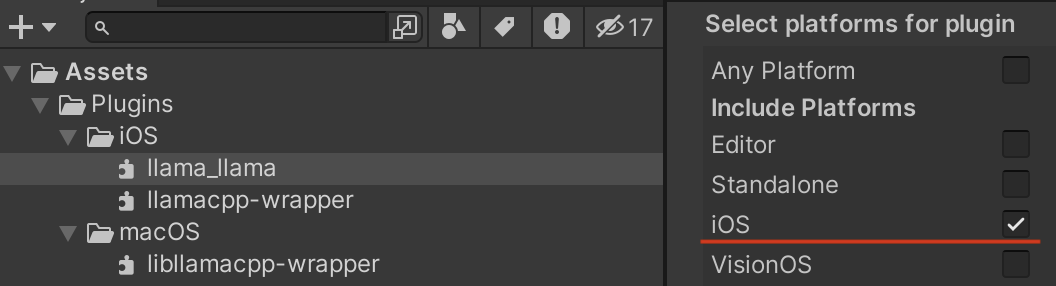
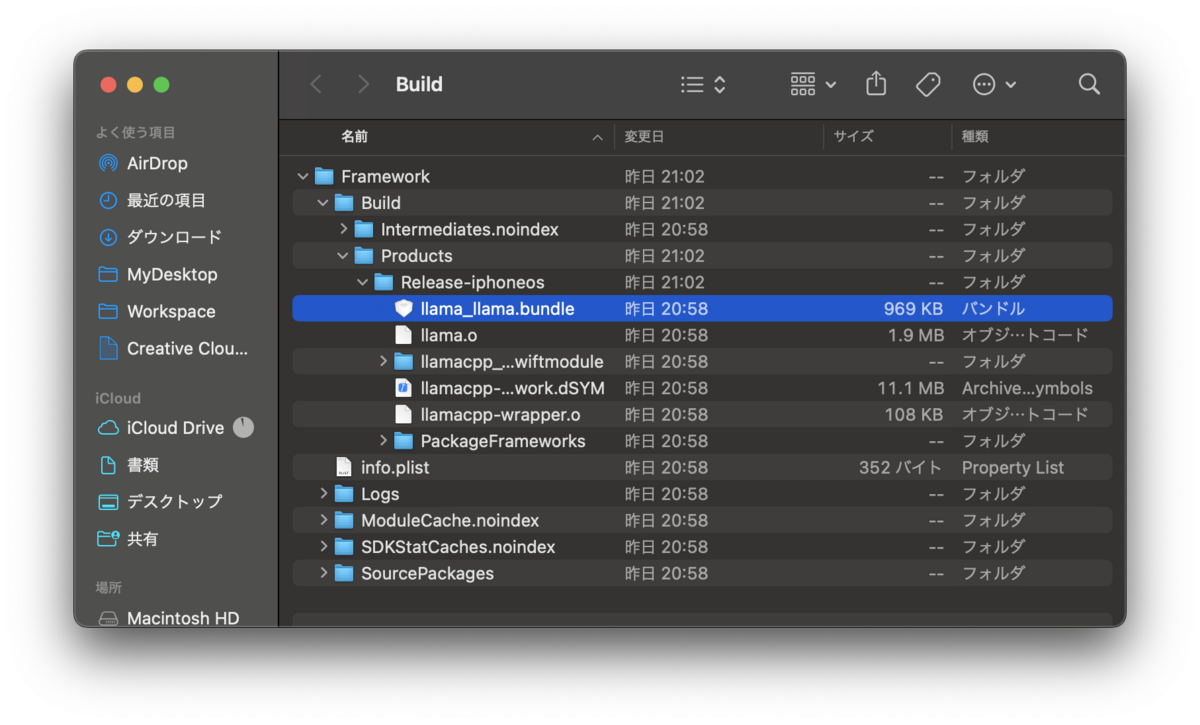
llama_llama.bundleが見つからない
上記クラッシュを回避したあと、無事にアプリが起動したのちに推論を実行したところ、 llama_llama.bundle が見つからないというエラーが発生しました。
これは、Swiftパッケージのビルド時に同時に生成されるバンドルファイルをプロジェクトに追加していなかったのが問題でした。なので、ビルドされたファイルの中にある llama_llama.bundle ファイルをUnityプロジェクトに追加する必要があります。(なお、macOS向けとiOS向けで内容が異なるので、それぞれのプラットフォーム向けに追加・設定する必要があります)
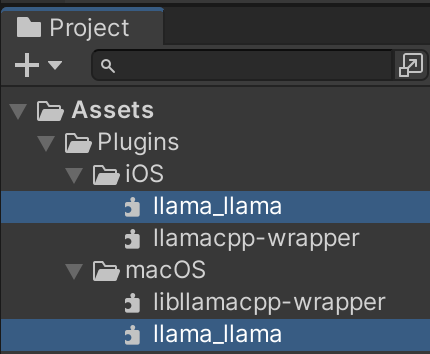
llama_llama.bundle はそれぞれのプラットフォーム向けになるようにインスペクタで設定する必要があります。