概要
以下の記事を参考に、最近リリースされたUnity製推論エンジンを試してみたのでそのメモです。
Barracudaとは?
Barracudaとは、ドキュメントにはこう記載されています。
Barracuda is lightweight and cross-platform Neural Net inference library. Barracuda supports inference both on GPU and CPU.
軽量でクロスプラットフォームなニューラルネットワークの推論ライブラリということですね。
そしてこちらのブログによるとUnity製のオリジナルだそうです。
セットアップ
BarracudaはPackage Managerから簡単にインストールできます。
インストールするにはWindow > Package ManagerからBarracudaを選択してインストールするだけです。
モデルの準備
これでC#からBarracudaを利用する準備は終わりです。
しかし、Deep Learningを利用して処理を行うためには訓練済みのモデルデータが必要です。
これがなければDeep Learningはなにも仕事をしてくれません。
Barracudaで扱えるモデル
Deep Learningを利用するためのフレームワークは多数出ています。有名どころで言えばTensorFlowなどですね。
そしてこうしたフレームワークごとにフォーマットがあり、そのフレームワークで訓練したデータは独自の形式で保存されます。
つまり言い換えればフレームワークごとにデータフォーマットが異なるということです。
そしてBarracudaでもそれ用のデータ・フォーマットで保存されたモデルデータが必要になります。
しかしBarracudaではONNX形式のモデルデータも扱うことができるようになっています。
ONNXとは?
ONNXはOpen Neural Network eXchangeの略です。(ちなみに『オニキス』と読むらしいです)
Openの名がつく通り、Deep Learningのモデルを様々なフレームワーク間で交換するためのフォーマット、ということのようです。
前述の通りBarracudaでも利用できます。
ONNXモデルの配布サイト
以下のリポジトリからいくつかの学習済みモデルがDownloadできます。
モデルの変換
Barracudaでは主要なフレームワークのモデルからBarracuda形式およびONNX形式に変換するためのツールを提供してくれています。
詳細は上記の記事を見てもらいたいと思いますが、どういう感じで変換を行うのかのコマンド例を載せておきます。
$ python tensorflow_to_barracuda.py ../mobilenet_v2_1.4_224_frozen.pb ../mobilenet_v2.nn Converting ../mobilenet_v2_1.4_224_frozen.pb to ../mobilenet_v2.nn Sorting model, may take a while...... Done! IN: 'input': [-1, -1, -1, -1] => 'MobilenetV2/Conv/BatchNorm/FusedBatchNorm' OUT: 'MobilenetV2/Predictions/Reshape_1' DONE: wrote ../mobilenet_v2.nn file.
モデルを利用して推論する(Style Chnage)
冒頭で紹介したこちらの記事からStyle Changeの方法を見ていきます。
(これがおそらく一番短くて分かりやすい例だと思います)
using UnityEngine; using Unity.Barracuda; public class StyleChange : MonoBehaviour { [SerializeField] private NNModel _modelAsset = null; [SerializeField] private RenderTexture _inputTexture = null; [SerializeField] private RenderTexture _outputTeture = null; private Model _runtimeModel = null; private IWorker _worker = null; private void Start() { // Load an ONNX model. _runtimeModel = ModelLoader.Load(_modelAsset); // Create a worker. // WorkerFactory.Type means which CPU or GPU prefer to use. _worker = WorkerFactory.CreateWorker(WorkerFactory.Type.Compute, _runtimeModel); } private void Update() { Tensor input = new Tensor(_inputTexture); Inference(input); input.Dispose(); } private void Inference(Tensor input) { _worker.Execute(input); Tensor output = _worker.PeekOutput(); output.ToRenderTexture(_outputTeture, 0, 0, 1/255f, 0, null); output.Dispose(); } private void OnDestroy() { _worker?.Dispose(); } }
だいぶ短いコードですね。これで映像を変換できるのだから驚きです。
ただし、複雑なネットワークを使っている場合はその分処理が重くなるので、リアルタイムなポストエフェクトとしては利用できないと思います。
このコードを実行すると以下のような結果が得られます。
(もちろん、設定するモデルによって出力の絵は変わります)

InputにRenderTextureを与え、OutputもRenderTextureで受け取っていますね。
入出力ともに画像なので利用イメージがしやすいと思います。
しかし(書いておいてなんですが)こうしたスタイルの変更というのはゲームではあまり使用されないかもしれません。
それよりも、物体検知やセグメンテーションなどでその真価を発揮するのではないかなと思っています。
ということで、次は物体検知についても書いておきます。
モデルを利用して推論する(物体検知)
以下のコードはこちらのGitHubのものを参考にさせていただいています。
(ファイルへの直リンク)
using System;
using Barracuda;
using System.Linq;
using UnityEngine;
using System.Collections;
using System.Collections.Generic;
using System.Text.RegularExpressions;
public class Classifier : MonoBehaviour
{
public NNModel modelFile;
public TextAsset labelsFile;
public const int IMAGE_SIZE = 224;
private const int IMAGE_MEAN = 127;
private const float IMAGE_STD = 127.5f;
private const string INPUT_NAME = "input";
private const string OUTPUT_NAME = "MobilenetV2/Predictions/Reshape_1";
private IWorker worker;
private string[] labels;
public void Start()
{
this.labels = Regex.Split(this.labelsFile.text, "\n|\r|\r\n")
.Where(s => !String.IsNullOrEmpty(s)).ToArray();
var model = ModelLoader.Load(this.modelFile);
this.worker = WorkerFactory.CreateWorker(WorkerFactory.Type.ComputePrecompiled, model);
}
private int i = 0;
public IEnumerator Classify(Color32[] picture, System.Action<List<KeyValuePair<string, float>>> callback)
{
var map = new List<KeyValuePair<string, float>>();
using (var tensor = TransformInput(picture, IMAGE_SIZE, IMAGE_SIZE))
{
var inputs = new Dictionary<string, Tensor>();
inputs.Add(INPUT_NAME, tensor);
var enumerator = this.worker.ExecuteAsync(inputs);
while (enumerator.MoveNext())
{
i++;
if (i >= 20)
{
i = 0;
yield return null;
}
};
// this.worker.Execute(inputs);
// Execute() scheduled async job on GPU, waiting till completion
// yield return new WaitForSeconds(0.5f);
var output = worker.PeekOutput(OUTPUT_NAME);
for (int i = 0; i < labels.Length; i++)
{
map.Add(new KeyValuePair<string, float>(labels[i], output[i] * 100));
}
}
callback(map.OrderByDescending(x => x.Value).ToList());
}
public static Tensor TransformInput(Color32[] pic, int width, int height)
{
float[] floatValues = new float[width * height * 3];
for (int i = 0; i < pic.Length; ++i)
{
var color = pic[i];
floatValues[i * 3 + 0] = (color.r - IMAGE_MEAN) / IMAGE_STD;
floatValues[i * 3 + 1] = (color.g - IMAGE_MEAN) / IMAGE_STD;
floatValues[i * 3 + 2] = (color.b - IMAGE_MEAN) / IMAGE_STD;
}
return new Tensor(1, height, width, 3, floatValues);
}
}
ちなみにStartメソッドで読み込んでいるテキストは分類の名称が改行区切りで入っているただのテキストファイルです。
以下はその一部。(ファイルへの直リンク)
background tench, Tinca tinca goldfish, Carassius auratus great white shark, white shark, man-eater, man-eating shark, Carcharodon carcharias tiger shark, Galeocerdo cuvieri hammerhead, hammerhead shark electric ray, crampfish, numbfish, torpedo stingray cock hen ...
入力画像から識別したラベルに対する確率を取得する
これらの動作の基本的な流れは以下です。
- 画像をテンソル化して入力データとする
- ニューラルネットワークを通して出力を得る
- 出力はラベル数と同じ数の1階テンソルで、値はそれぞれの分類の確度(%)
- あとは確度に応じて望む処理をする
という具合です。
そしてその出力部分を抜粋すると以下のようになっています。
var output = worker.PeekOutput(OUTPUT_NAME); for (int i = 0; i < labels.Length; i++) { map.Add(new KeyValuePair<string, float>(labels[i], output[i] * 100)); }
output[i] * 100としている箇所が確率を%に変換している部分ですね。
つまり、該当番号(i)のラベルである確率をDictionary型の変数に入れて返しているというわけです。
取得するテンソルはvar output = worker.PeekOutput(OUTPUT_NAME);でアクセスしています。
そしてこのOUTPUT_NAMEはprivate const string OUTPUT_NAME = "MobilenetV2/Predictions/Reshape_1";と定義されています。
この文字列は訓練されたモデルのネットワークの変数名でしょう。
つまり推論の結果をこれで取得している、というわけですね。
モデルのInput / Outputを確認する
前述したように、モデルへのInputとOutputを明示的に指定する必要があり、そのための文字列を知る必要があります。
そのための情報はインスペクタから確認することができます。
インポートしたモデルファイルを選択すると以下のような情報が表示されます。
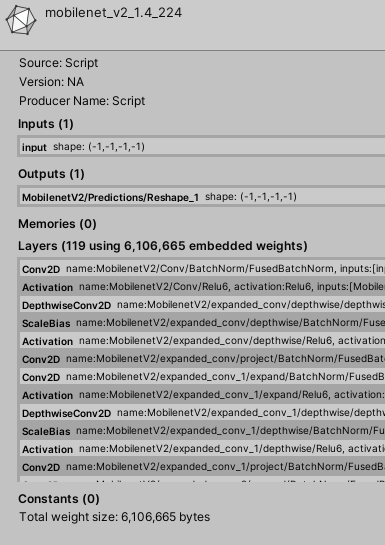
この図のInputs (1)とOutputs (1)がそれに当たります。
その下のLayersはニューラルネットワークのレイヤーの情報です。
つまりどんなネットワークなのか、ということがここで見れるわけですね。
画像として出力されるモデルかどうか確認する
ちなみにStyle Changeのところで書いたように、画像自体を変換して出力するネットワークなのかどうかは以下のInputs / Outputsを確認すると分かると思います。
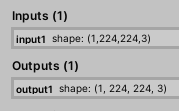
入力が画像サイズで、出力も画像サイズになっている場合はそれが画像として出力されていると見ることが出来ます。
出力が[1, 224, 224, 3]となっているのは224 x 224サイズの3チャンネル(RGB)を1つ出力することを意味しているわけですね。
まとめ
Deep Learning(ニューラルネットワーク)は、極論で言えば巨大な関数であると言えると思います。
入力となる引数も巨大であり、そこから目的の出力を得ること、というわけですね。
の、が入力(つまり今回の場合は画像)で、その結果(どのラベルの確率が高いか)が
、というわけです。
これを上記の物体検知に当てはめてC#で書き直すと、
// inferenceは「推論」を意味する英単語 Dictionaly<string, float> map = Inference(_inputTexture);
という感じですね。
最近はDeep Learningについてずっと調査をしています。
そこでの自分の大まかな理解を書いておくと、この巨大な関数を解くためのパラメータを『機械学習』で調整させる。
その調整する方法が『パーセプトロン』をベースとする『ニューラルネットワーク』を利用して行っている。
そしてこの調整されたパラメータとネットワーク構成がつまりは訓練済みモデル(データ)というわけです。
なのでそのパラメータを利用した関数を通すとなにかしらの意味がある出力が得られる、というわけなんですね。
もちろん、そのネットワークをどう組むか。それがどう実現しているのか。基礎を学ぼうとすると膨大な知識が必要になります。
しかし、こと利用する視点だけで見ればなんのことはない、ただの関数実行だ、と見ると利用がしやすいのではないかと思います。
これを機に色々とUnity上でディープラーニングを使って色々とやっていきたいと思います。