概要
最近、ARでSemantic Segmentaionを試そうと色々やっているのでそのメモです。
最終的には拾ってきたDeepLabモデルを変換して実際に動かすまでをやってみようと思います。
今回の記事はこちらを参考にさせていただきました。
元々TensorFlow LiteにはUnity Pluginがあるようで、上記ブログではそれを利用してUnityのサンプルを作ってるみたいです。
サンプル自体もTensorFlowにあるものを移植したもののようです。
公開されているUnityのサンプルプロジェクトは以下です。
今回の記事もこれをベースに色々調べてみたものをまとめたものです。
今回試したものは、以下のような感じで動作します。
全体を概観する
まずはTensorFlowについて詳しくない人もいると思うのでそのあたりから書きたいと思います。
TensorFlow Liteとは
いきなりサンプルの話にはいる前に、ざっくりとTensorFlow Liteについて触れておきます。
TensorFlow Liteとは、TensorFlowをモバイルやIoTデバイスなど比較的非力なマシンで動作させることを目的に作られたものです。
つまり裏を返せば、通常のTensorFlowはモバイルで動作させるには重くて向いていないということでもあります。
詳細についてはTensorFlow Liteのサイトをご覧ください。
こちらの記事も参考になります。
TensorFlow Liteのモデル
TensorFlow Liteのモデルは.tfliteという拡張子で提供され、主に、TensorFlow本体で作られた(訓練された)データを変換することで得ることができます。サイトから引用すると以下のように説明されています。
To use a model with TensorFlow Lite, you must convert a full TensorFlow model into the TensorFlow Lite format—you cannot create or train a model using TensorFlow Lite. So you must start with a regular TensorFlow model, and then convert the model.
特にこの「you must convert a full TensorFlow model into the TensorFlow Lite format.」というところからも分かるように、TensorFlow LiteではTensorFlowのすべての機能を使えるわけではないということです。
逆に言えば、軽量化・最適化を施して機能を削ることでエッジデバイス(スマホやIoTデバイス)でも高速に動作するというわけなんですね。
DeepLabとは
今回試したのは『DeepLab』と呼ばれる、Googleが提案した高速に動作するセマンティックセグメンテーションのモデル(ネットワーク)です。
セマンティックセグメンテーションについては後日書く予定ですが、こちらのPDFがだいぶ詳しく解説してくれているのでそちらを見るとより理解が深まるかと思います。
DeepLabについてはGoogleのブログでも記載があります。
ものすごくざっくり言うと、セマンティックセグメンテーションとは、画像の中にある物体を認識しその物体ごとに色分けして分類する、という手法です。
手法自体はいくつか提案されており、今回使用したDeepLabもそうした手法のうちのひとつです。
特徴としてはモバイルでも動作するほど軽く、高速に動くという点です。
そのためARで利用することを考えた場合に、採用する最有力候補になります。(なので今回試した)
ちなみにGitHubにも情報が上がっています。
ひとまず、前提知識として知っておくことは以上となります。
次からは実際にUnityで動かす過程を通して、最終的には拾ってきたDeepLabモデルを変換して実際に動かすまでをやってみようと思います。
Unityサンプルを動かす
Unityのサンプルを動かしてみましょう。
まずはGitHubからダウンロードしてきたものをそのまま実行してみます。
動画を見てもらうと自転車と車に対して反応しているのが分かるかと思います。
サンプルプロジェクトに含まれるモデルはこちらで配布されているものです。
スターターモデルと書いてあるように、若干精度は低めかなという印象です。
本来的にはここから自分の目的にあったものにさらに訓練していくのだと思います。
サンプル以外のモデルを試す
サンプルに含まれているモデルが動くことが確認できました。
次は別のモデルを試してみることにします。
モデルを変換する
さて、別のモデルといってもイチから訓練するものではなく、すでに訓練され公開されているものを探してきてそれを変換したものを使ってみたいと思います。
これによってサンプルとの違いができ、より深く動作を確認できると思います。
ということで参考にさせてもらったのが以下のリポジトリです。
ここのREADMEの下の方にあるリンクからモデルをダウンロードしてきます。
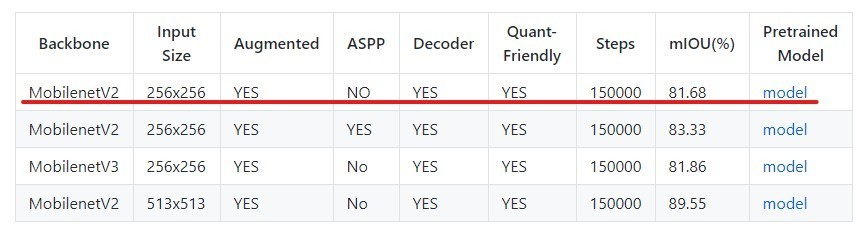
TensorFlow Liteのモデルへの変換について
TensorFlowで訓練したモデルをLite版へと変換していきます。
ちなみにTensorFlowのモデルにはいくつかの形式があり、以下の形式が用いられます。
- SavedModel
- Frozen Model
- Session Bundle
- Tensorflow Hub モジュール
これらのモデルについては以下のブログを参照ください。
今回はこの中の『Frozen Model』で保存されたものを扱います。
ちなみにもし自分で訓練データを作成する場合は注意しなければならない点があります。
前節で書いたように、TensorFlow Liteはいくつかの機能を削減して軽量化を図るものです。
そのため、TensorFlowでは問題なく動いていたものが動かないことも少なくありません。
このあたりについてはまだ全然詳しくないのでここでは解説しません。(というかできません)
以下の記事が変換についてとても詳しく書かれているので興味がある方は参照してみてください。
ちなみに以下の記事は「量子化(Quantization)」を目的とした変換に焦点を絞っています。
以下、余談。
量子化(Quantization)とは
上記記事では以下のように説明されています。
上記のリポジトリから Freeze_Graph (.pb) ファイルをダウンロードします。 ココでの注意点は ASPP などの特殊処理が入ったモデルは軒並み量子化に失敗しますので、なるべくシンプルな構造のモデルに限定して取り寄せることぐらいです。
※ ... ちなみにASPP - Atrous Spatial Pyramid Poolingの略です。
ASPPがなにかを調べてみたら以下の記事を見つけました。
記事には以下のように記載されています。
- 画面いっぱいに写っていようと画面の片隅に写っていようと猫は猫であるように,image segmentationではscale invarianceを考慮しなければならない. 著者はAtrous Convolutionのdilationを様々に設定することでこれに対処している(fig.2). 著者はこの技法を”atrous spatial pyramid pooling”(ASPP)と呼んでいる.
さらに該当記事から画像を引用させてもらうと、

おそらくこの画像の下の様子がピラミッドに見えることからこう呼んでいるのだと思います。
が、量子化に際してこの技法が含まれていると変換できないようなのでここではあまり深堀りしません。
簡単に量子化について触れておくと、以下の記事にはこう説明されています。
情報理論における量子化とは、アナログな量を離散的な値で近似的に表現することを指しますが、本稿における量子化は厳密に言うとちょっと意味が違い、十分な(=32bitもしくは16bit)精度で表現されていた量を、ずっと少ないビット数で表現することを言います。
ニューラルネットワークでは、入力値とパラメータから出力を計算するわけですが、それらは通常、32bitもしくは16bit精度の浮動小数点(の配列)で表現されます。この値を4bitや5bit、もっと極端な例では1bitで表現するのが量子化です。1bitで表現する場合は二値化(binarization)という表現がよく使われますが、これも一種の量子化です。
量子化には、計算の高速化や省メモリ化などのメリットがあります。
要するに、本来はintやfloatなど「大きな容量(16bit ~ 32bit)」を使うものをより小さい容量でも同じような精度を達成する方法、ということでしょうか。
これにはメモリ的なメリットや、単純に演算数の削減が見込めそうです。
モバイルではとにかくこのあたりの最適化は必須になるので量子化は必須と言ってもいいと思います。
(そういう意味で、量子化モデルの変換記事はめちゃめちゃ濃いので一度目を通しておくといいと思います)
が、後半で説明するtfliteへの変換でQuantizationのパラメータを設定するとうまく動作しなかったのでさらなる調査が必要そうです・・・。
閑話休題。
モデルの入力・出力を調べる
ではモデルを変換していきましょう。
モデルを変換するためにはいくつかの情報を得なければなりません。
ここでは詳細は割愛しますが、ディープラーニングではニューラルネットワークへの入力と出力(Input / Output)が大事になってきます。
ものすごくざっくり言えば、ディープラーニングはひとつの関数です。
プログラムでも、関数を利用したい場合はその引数と戻り値がなにかを知る必要があることに似ています。
自分でネットワークを構築し訓練したものであればすでに知っている情報かもしれませんが、だいたいの場合はどこからか落としてきたモデルや、あるいは誰かの構築したネットワークを利用するというケースがほとんどでしょう。
そのため入力と出力を調べる必要があります。
調べ方については上のほうで紹介したこちらの記事が有用です。
そこで言及されていることを引用させていただくと、
INPUTは Input、 形状と型は Float32 [?, 256, 256, 3]、 OUTPUTは ArgMax、 形状と型は Float32 [?, 256, 256] のようです。 なお一見すると ExpandDims が最終OUTPUTとして適切ではないか、と思われるかもしれませんが、 実は Semantic Segmentation のモデルにほぼ共通することですが ArgMax を選定すれば問題ありません。
とあります。
ここで言及されている名前はネットワーク次第なので毎回これになるとは限りません。
しかし
実は Semantic Segmentation のモデルにほぼ共通することですが ArgMax を選定すれば問題ありません。
というのはとても大事な点なので覚えておきましょう。
ちなみにモデルの中身を可視化するツールがあります。
以下の『Netron』というものです。
Webサービスを利用して見てもいいですし、アプリもあるのでよく使う場合はインストールしておいてもいいでしょう。
では先ほど落としてきたモデルを読み込ませて見てみましょう。

入力はInputという名前で、入力の型はfloat32、入力のサイズは256 x 256の3チャンネルというのが分かります。
とても簡単に可視化できるのでとてもオススメのツールです。
続けて出力も見てみましょう。

参考にした記事に習ってArgMaxの部分を見てみます。
確認すると出力はArgMaxという名前でint32型、256 x 256の出力になるようです。
モデルの変換には「tflite_convert 」コマンドを使う
情報が揃ったのでダウンロードしてきたモデルを変換します。
変換にはtflite_convertコマンドを利用します。
今回の変換では以下のように引数を指定しました。
tflite_convert ^ --output_file=converted_frozen_graph.tflite ^ --graph_def_file=frozen_inference_graph.pb ^ --input_arrays=Input^ --output_arrays=ArgMax ^ --input_shapes=1,256,256,3 ^ --inference_type=FLOAT ^ --mean_values=128 ^ --std_dev_values=128
引数に指定している--input_arraysと--output_arraysが、先ほど調べた名前になっているのが分かります。
さらに--input_shapesには入力の形として先ほど調べた256 x 256を指定しています。
これを指定することで適切に変換することができます。
では変換されたモデルをNetronで可視化してみましょう。

内容が変化しているのが分かります。
これをUnityのサンプルプロジェクトに入れて利用してみます。

これであとは実行するだけ・・・にはいきません。
drive.google.com ※ 変換したモデルを念の為公開しておきます。
モデルに合わせてC#を編集する
実はサンプルで用意されているDeepLabスクリプトはサンプルに含まれているモデルに合わせて実装されているため、今回のケースの場合は少し修正をしなければなりません。
なのでNetronによって確認できる型や形状に定義を変更します。
ということでDeepLabクラスを修正します。
今回修正した内容のdiffは以下です。

さて、さっそく変換したモデルを読み込ませて使ってみましょう。
・・・と勢い込んでビルドしてみるものの動かず。Logcatで見てみると以下のようなエラーが表示されていました。
08-07 10:50:49.160: E/Unity(6127): Unable to find libc 08-07 10:50:49.163: E/Unity(6127): Following operations are not supported by GPU delegate: 08-07 10:50:49.163: E/Unity(6127): ARG_MAX: Operation is not supported. 08-07 10:50:49.163: E/Unity(6127): BATCH_TO_SPACE_ND: Operation is not supported. 08-07 10:50:49.163: E/Unity(6127): SPACE_TO_BATCH_ND: Operation is not supported. 08-07 10:50:49.163: E/Unity(6127): 53 operations will run on the GPU, and the remaining 31 operations will run on the CPU. 08-07 10:50:49.163: E/Unity(6127): TensorFlowLite.Interpreter:TfLiteInterpreterCreate(IntPtr, IntPtr) 08-07 10:50:49.163: E/Unity(6127): TensorFlowLite.Interpreter:.ctor(Byte[], InterpreterOptions) 08-07 10:50:49.163: E/Unity(6127): TensorFlowLite.BaseImagePredictor`1:.ctor(String, Boolean) 08-07 10:50:49.163: E/Unity(6127): TensorFlowLite.DeepLab:.ctor(String, ComputeShader) 08-07 10:50:49.163: E/Unity(6127): DeepLabSample:Start()
いくつかのオペレーションがGPUに対応していないためのエラーのようです。
ということで、以下の部分をfalseにして(GPU未使用にして)ビルドし直してみます。
(ちなみにiOSではGPUオンの状態でも問題なく動いたのでAndroid版の問題のようです)
public DeepLab(string modelPath, ComputeShader compute) : base(modelPath, true) { // ... 後略
これを、
public DeepLab(string modelPath, ComputeShader compute) : base(modelPath, false) { // ... 後略
こうします。
この第二引数がGPUを使うかどうかのフラグの指定になっています。
あとはこれをビルドし直して動かすだけです。
(すでに冒頭でも載せていますが)これで無事に動きました!
最後に
これがゴールではなくむしろスタート地点です。
ここから、独自のモデルの訓練をして目的に適合する結果を得られるように調整していかなければなりません。
が、ひとまずはTensorFlowで作られたモデルをtflite形式に変換して動作させるところまで確認できたので、あとはこの上に追加して作業をしていく形になります。
ここまで来るのは長かった・・・。
やっと本題に入れそうです。